
The topic of scaling DevOps is far from new. As many of us painfully realize, it’s difficult to go beyond the little science experiment (an experiment with one application team—usually an internal application—with the luxury of being 100% cloud-native and container-based, as well as having 100% kick-ass developers that are 100% Infrastructure-as-Code experts). Such initiatives tend to provide very little insight on how to go on from there. They give no clues into how to form a viable strategy for cross-organization adoption of practices that make DevOps work for the organization, and not the other way around.
I recently came across a solid white paper by Mark Debney, DevOps at Scale in The Real World, where he explains how organizations should take up this challenge.
Feels Like DevOps Culture
Mark’s practical approach got my attention. It focuses on developing real capabilities rather than emphasizing the lack of culture:
“In short, let’s not get hung up on creating a ‘culture of DevOps’, but instead focus on targeting and improving capabilities that allow us to deliver code to production faster and more reliably. More importantly, let’s provide value to the organization’s profits, productivity and customer satisfaction.”
This resonated with me. The DevOps community has been going around in circles for some time with the culture problem—and not necessarily getting to a conclusion (how many talks have I attended where the bottom line was “The no.1 barrier is culture”? Lots. Including my own…).
Saved by Coders
This culture problem makes many of us believe that the answer is developers taking over. Developers understand the culture, they understand the need for speed. Most importantly: they have the skills to get there. We take the newest parts of our businesses and put them in the hands of very talented and expensive developers, who seem capable of operating their stack, and wish them good luck. We work under the intoxicating effect of words that make people like me quietly nod in approval (Continuous! Kubernetes! Immutable Infrastructure! Infrastructure as Code! GitOps! The list goes on).
But there is huge risk in throwing all responsibility on developers, encouraging the chase of shiny technologies, and assuming that developers will naturally scale it.
It may feel like adopting a DevOps culture. It may make developers feel empowered, but will this result in our business performing better? Does it make sense if 10-15% of our most talented staff is channeling their energy gluing together Jenkins with Helm charts, Terraform configuration files, Prometheus and Grafana, sprinkling incident management on top, while ignoring the security team? Does it still make sense when we get the cloud bill? Does it still make sense when we need to comply with GDPR or HIPAA? Does it really serve a business purpose, or just sounds good?
Focusing on the Needs of Multiple Teams
In his white paper, Mark suggests to focus on the needs of multiple development teams, and on the flexibility and stability of the DevOps platform that has to support multiple teams.
He is not the only one who thinks that. The DORA (DevOps Research and Assessment) 2019 state of DevOps report made a similar observation:
“Creating a continuous integration platform that makes it easy for teams to get fast feedback on their automated tests can be a significant force-multiplier when used across several teams in an organization.”
Turning the Capabilities of DevOps into Products and Services
Mark reviews different approaches and implementations that we see in the industry—from Site Reliability Engineering (SRE) to DevSecOps, FinOps, AIOps, and more. But he summarizes that these options are all built around the premise that there is a capability, or a number of capabilities, that cannot be addressed without specialist knowledge. This might be security in the case of DevSecOps, or cost optimization within FinOps and so on.
“If we want to scale these capabilities beyond a single team, and more importantly retain the knowledge, we need to rethink how we structure DevOps teams, we need to start turning the capabilities of DevOps into products and services of which development teams are the consumers.”
I see more DevOps and ITOps professionals that speak the same language. I believe it was Gartner that coined the term Platform Ops, but whether the exact term is used or not—the same ideas keep popping up. Scale can’t be achieved if we expect our developers to reinvent the wheel.
The essence of Platform Ops is turning DevOps capabilities into products and services:
“The role of a Platform Ops team is to provide operational services to development teams in a way that allows them to go on to self-serve.”
This requires separating the core business from the platform that supports the development of the core business. It allows integrating best practices, and it provides consistency and empowerment that makes DevOps culture possible in large enterprise organizations.
I liked this diagram that captures the principals:
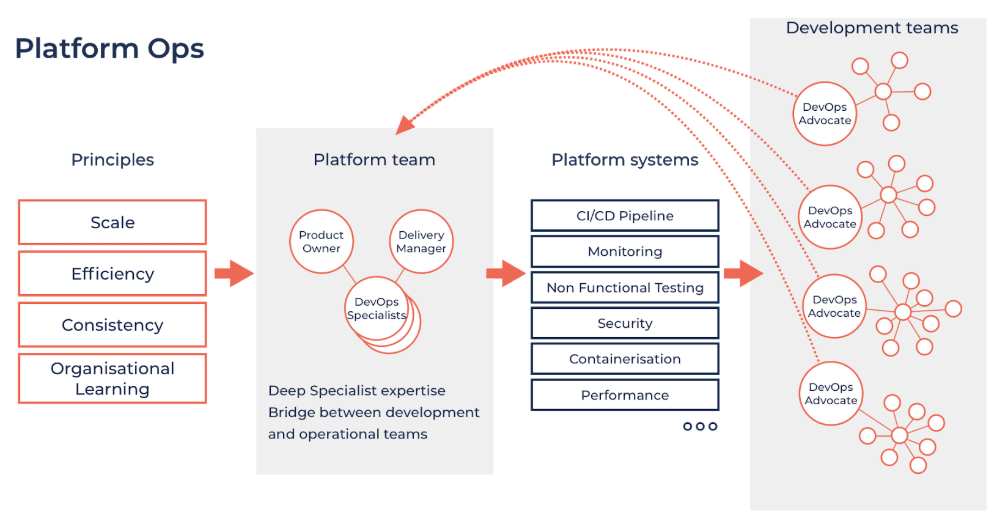
Mark mentions the role of Platform Ops in providing a successful handoff in governance and security element from traditional infrastructure and operations team to developers:
“If organizations are able to provide a self-service platform that enables their developers to quickly, reliably and safely deploy code—while at the same time ensuring best practice, governance and access to the latest technologies is baked in—then they will not only be able to scale the DevOps capabilities of their development teams, but also create a true and lasting DevOps culture throughout the organization.”
A very similar approach is described in Google’s ”Site Reliability Engineering: How Google Runs Production Systems”. Chapter 32 discusses the evolution in the SRE engagement model at Google:
“Another way, perhaps the best, is to short-circuit the process by which specially created systems with lots of individual variations end up “arriving” at SRE’s door. Provide product development with a platform of SRE-validated infrastructure, upon which they can build their systems. This platform will have the double benefit of being both reliable and scalable. This avoids certain classes of cognitive load problems entirely, and by addressing common infrastructure practices, allows product development teams to focus on innovation at the application layer, where it mostly belongs.”
What are Platform Ops Responsibilities?
A Platform Ops team is a horizontal team. It is responsible for building the DevOps platform that multiple applications teams can use to build products.
The team is responsible for DevOps and ITOps aspects that aren’t part of the core business:
- Value stream delivery and CI/CD
- Infrastructure automation
- Artifact repository
- Monitoring/AIOps
- Alerting and emergency response
- Cloud costs and infrastructure optimization
- Infrastructure and application security
- Secret management
- Metrics
The above is rarely found in a single product. In fact, the global trend in the past decade has been to break it down into a gazillion open source pieces. But we also see a countertrend of merging these capabilities—driven by Atlassian, Microsoft, GitLab, JFrog, and others. Forrester principal analyst Chris Condo wrote about it last year, and he anticipated that “DevOps Tool Consolidation Will Continue”.
Whether these capabilities come from three or fifteen different elements, the Platform Ops team needs to deliver developer experience. The team has to integrate and provide the platform as-a-service to the development teams. And don’t forget maintaining it over time—someone needs to host and upgrade non-SaaS components (Jenkins, for example, or the various plug-ins that the DevOps community bestows upon us) and make sure that the platform continuously works as expected.
Eventually, the Platform Ops team is measured in how quickly a new development team can be onboarded, and in the added-value to developers’ experience over time.
Is Platform Ops the right approach for scaling DevOps at a large organization? I think it is the best approach—for now. What do you think?