
The most dangerous infrastructure failure isn’t the one that crashes your pipeline. It’s the one that deploys cleanly, passes review, and sits quietly in production, misconfigured, non-compliant, and completely invisible until something goes wrong.
That’s the failure mode that GenAI has made easier to produce at scale. Not broken code. Plausible code. And in infrastructure, plausible-but-wrong can be far more costly than obviously broken.
GenAI is now deeply embedded in infrastructure work. It writes Terraform and Bicep. It explains noisy logs. It summarizes compliance documentation that no one had time to read. In some cases, it suggests fixes that seem, at first glance, genuinely sensible.
That speed and fluency quickly became normal for infrastructure engineers, which almost no one saw coming.
But speed has a habit of hiding tradeoffs. And in infrastructure, those tradeoffs don’t stay hidden for long.
The Core Problem: Infrastructure Amplifies Every GenAI Failure Mode
Misconfiguration is already the leading cause of cloud security incidents. According to Gartner, through 2025, 99% of cloud security failures will be the customer’s fault, and misconfiguration is the primary mechanism. Meanwhile, AI-assisted code generation is being adopted far faster than the governance tooling designed to validate it.
That gap is where risk lives.
Infrastructure is uniquely sensitive to AI failure modes for three compounding reasons:
- Small errors have large blast radii. A single IAM wildcard, permissive network rule, or misconfigured scaling parameter can affect dozens of downstream systems simultaneously.
- Rollback is expensive. Infrastructure changes are stateful, tightly coupled to data, identity, and external dependencies. Unlike application code, you can’t always just redeploy.
- Constraints are external and invisible to the model. Compliance requirements, contractual obligations, and internal security policy cannot be reliably inferred from code structure alone. The model has no way of knowing what it doesn’t know about your environment.
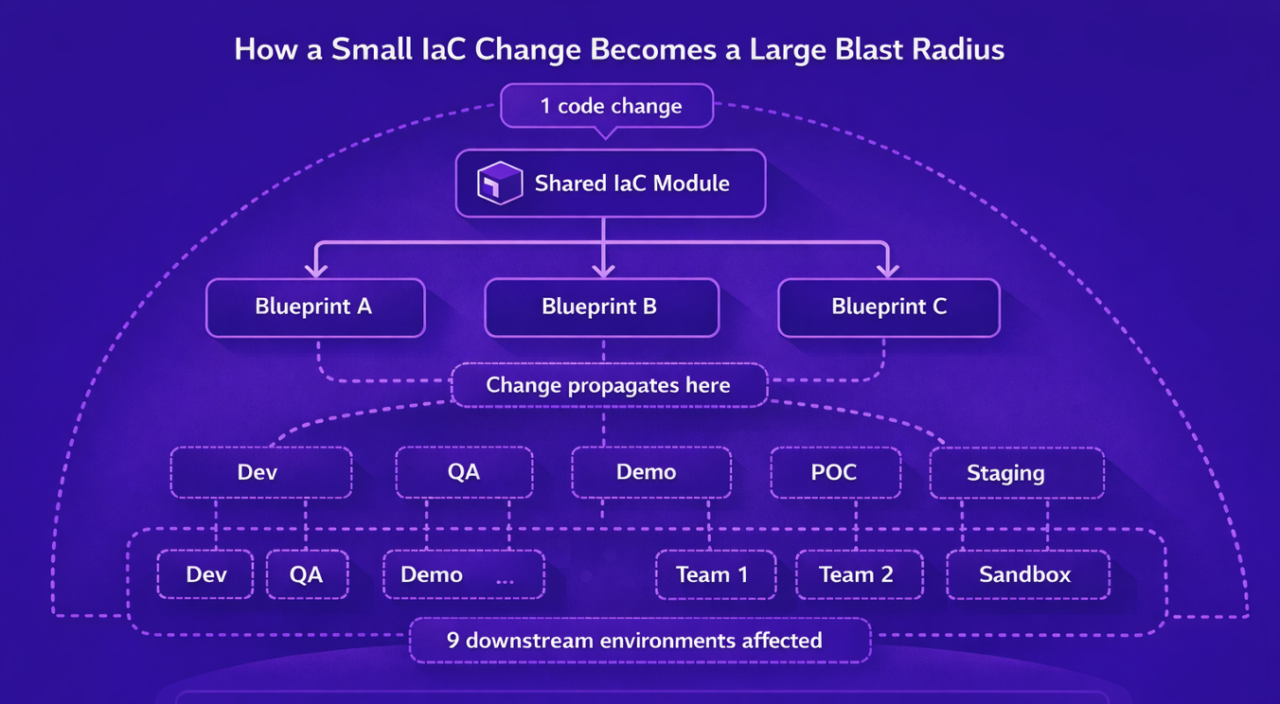
Diagram 1 – Small errors, large blast radii
The most common AI-generated infrastructure failures aren’t syntax errors, they’re wrong assumptions, incomplete reasoning, and mis-calibrated boundary handling. And those are the hardest failures to catch.
When “Passing” Isn’t the Same as “Correct”
Consider a routine Terraform change. An AI assistant suggests a security group configuration. It’s clean, well-structured, and consistent with how similar resources look in the codebase. Terraform validates it. The cloud provider accepts it. It applies without errors.
It also allows inbound traffic from 0.0.0.0/0, the entire internet, across admin, database, and internal service ports.
Nothing failed. Everything passed. The exposure is live.
This is what makes AI-generated IaC uniquely risky: the output carries the appearance of prior validation, even when critical assumptions were never explicitly verified. Reviewers implicitly trust the structure and confidence of the change, perform fewer independent checks, and accept assumptions they would normally challenge if the same configuration came from a junior engineer.
The result isn’t an unreviewed change. It’s a mis-reviewed one, where risk is approved without ever being explicitly evaluated. That distinction matters enormously, because mis-reviewed changes are much harder to catch in process and much more expensive to remediate after the fact. Catching a misconfiguration at the review stage costs minutes. Catching it during an audit or incident response can cost hundreds of thousands of dollars and significant reputational damage.
The Real Failure Mode: Confident and Wrong
GenAI doesn’t just produce incorrect output, it produces incorrect output with complete confidence. OpenAI explicitly acknowledges this in its truthfulness guidance and in the GPT-4 technical limitations documentation. In IaC workflows, that confident wrongness shows up as assertions like “secure by default,” “this meets compliance,” or “that limit doesn’t exist”, delivered with the same tone and structure as correct output.
There’s no uncertainty signal. No hedging. No flag that says this assumption was not verified against your actual environment.
Three real-world examples illustrate how this pattern plays out when organizations treat AI output as authoritative:
Fabricated citations (Mata v. Avianca, 2023). Lawyers submitted a legal brief containing case citations generated by ChatGPT. The cases didn’t exist, but the citations were well-formatted, contextually appropriate, and passed initial review. The IaC equivalent isn’t a fabricated resource name (schema validation catches those quickly). It’s a fabricated assumption, about what your compliance baseline requires, what your security policy permits, or what your logging standard mandates, rendered in clean, deployable code.
Invented policy (Moffatt v. Air Canada, 2024). A customer asked Air Canada’s chatbot about bereavement fare policies. The bot described a retroactive discount policy that didn’t exist. The customer relied on it, was denied the refund, and the tribunal held Air Canada liable for its chatbot’s misinformation. Air Canada was ordered to pay C$812 in damages. When models lack complete information about your internal procedures, they don’t say “I don’t know”, they synthesize a plausible answer. Ask an AI about “our logging baseline” and you may get a confident hallucination that sounds like established internal policy. If it lands in code, it becomes institutional misinformation at scale.
Authoritative but wrong (NYC small-business chatbot, 2024). Reporting from The Markup and Reuters showed New York City’s AI chatbot for small businesses sometimes gave advice that would violate local laws, delivered with the same confident, authoritative tone as correct guidance. The NYC chatbot was shut down in February 2026 by the incoming mayor, who called it “functionally unusable”. Infrastructure is full of law-like constraints: regulatory rules, contractual requirements, internal security policy, audit controls. A model can recommend something that works technically and fails compliance because the constraints were never encoded as guardrails.
The thread connecting all three isn’t that AI systems are unreliable in obvious ways. It’s that they’re unreliable in ways that pass initial scrutiny, and that’s a fundamentally different problem to solve.
Why Better Prompts Aren’t Enough
The natural response to these risks is to try to prompt your way out of them: more detailed instructions, clearer constraints, better context in the system prompt. This helps at the margins, but it doesn’t solve the structural problem.
Policy that lives in prompts can be overridden, forgotten, or simply not passed along when someone uses a different tool or workflow. It doesn’t enforce anything, it just requests. And it scales as poorly as any other manual process: the more teams, engineers, and environments you add, the more opportunities there are for the guardrails to be absent.
What infrastructure governance actually requires isn’t better AI behavior. It’s a structural separation between what AI generates and what gets deployed, with machine-enforced constraints at the boundary that don’t depend on any individual reviewer catching the right thing at the right moment.
That means:
- Policy as code, not policy as prompt. Constraints should be explicit, versioned, and enforced automatically, not hoped for in a review comment.
- Human judgment where context matters. Reviewers should be making architectural and business decisions, not manually checking whether encryption is enabled or whether a network rule is too permissive.
- Automated enforcement where discipline matters. Security baselines, cost guardrails, compliance requirements, these shouldn’t require human attention every time. They should simply be enforced.
- Continuous state validation. Approved configurations drift. Environments change after deployment. Point-in-time review isn’t enough if nothing is watching what happens afterward.
This division of labor, human judgment for context-dependent decisions, machine enforcement for discipline-dependent ones, is what responsible AI-assisted infrastructure actually looks like.
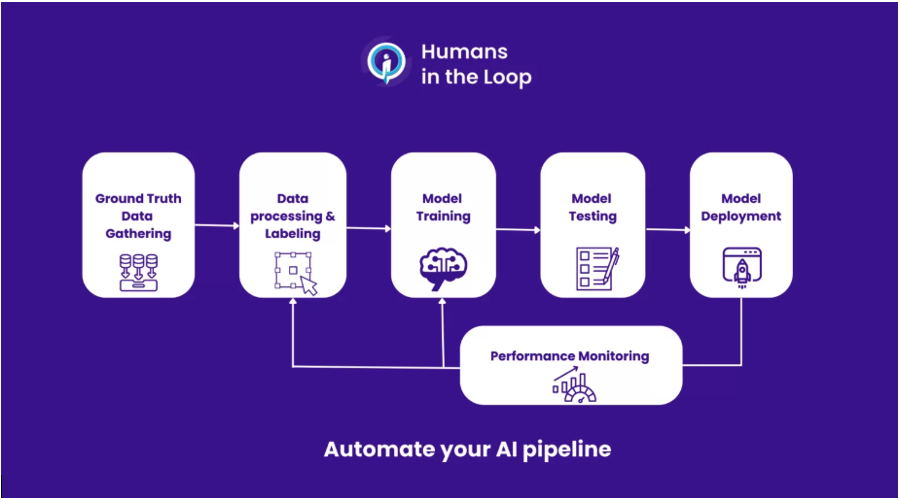
Diagram 2 – Humans in the Loop
How Quali Torque Puts This Into Practice
This is precisely the gap Quali Torque is designed to close.
Rather than treating governance as a checklist that teams apply after AI generates something, Torque makes human-in-the-loop validation and policy enforcement a structural property of the delivery pipeline itself. The guardrails aren’t optional. They’re built in.
Concretely, Torque lets teams encode budget limits, security requirements, and compliance rules as enforceable policy, so environments that violate those constraints are rejected before they launch, regardless of how the underlying IaC was generated. This means AI-generated configurations that look correct but break security or cost intent don’t slip through because a reviewer was tired or under time pressure.
Torque also supports self-service environment launches through reusable Environment-as-Code blueprints, which removes the bottleneck of ticket-based access requests without removing accountability. Engineers move faster; governance doesn’t get bypassed to make that happen.
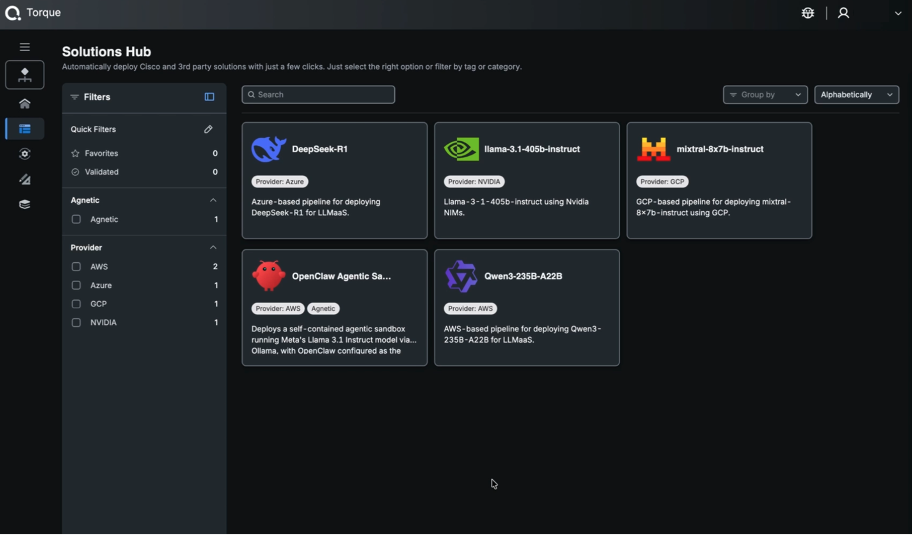
Diagram 3 – Torque Solutions Hub
Once environments are running, Torque monitors infrastructure state continuously, catching drift and unauthorized changes that occur after deployment, when point-in-time review has long since ended. It also identifies idle and underutilized resources, which directly addresses the cost exposure that comes with AI-assisted provisioning at scale.
Torque’s grain architecture extends this further. Security tooling like Fortline can be embedded directly into environment blueprints as a grain, meaning runtime security enforcement isn’t configured separately after the fact, it’s a first-class component of the environment itself. When the environment launches, Fortline launches with it. When the deployment is verified compliant, that status reflects the Fortline enforcer running and confirming it, not a one-time check at the gate. Security becomes a continuous, structural property of every environment that blueprint produces.
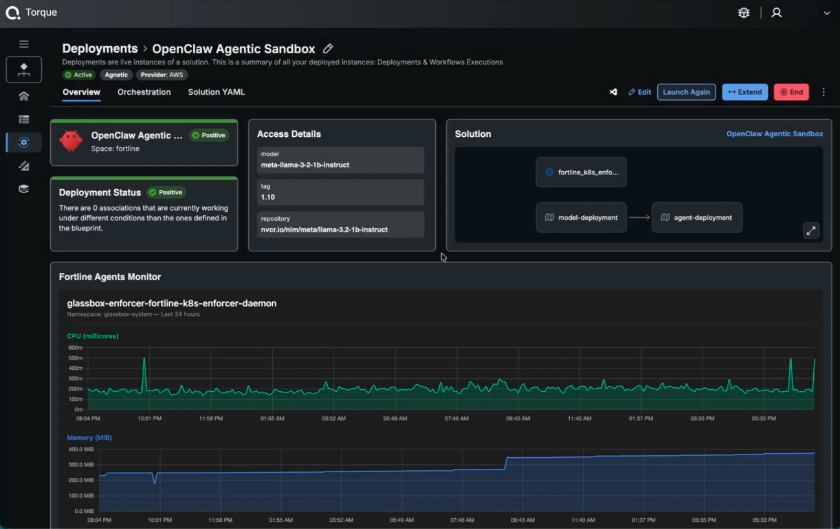
Diagram 4 – Fortline Active Deployment Monitoring
The result is a delivery pipeline where GenAI can contribute meaningfully to infrastructure velocity without quietly rewriting the standards that the organization depends on.
Conclusion: Speed Without Guardrails Isn’t Efficiency
GenAI drafts faster, explains faster, and reduces real repetitive toil. Those benefits are genuine and worth keeping.
But authoritative-sounding output isn’t authoritative truth. A configuration that deploys cleanly isn’t necessarily a configuration that’s correct, compliant, or safe. And the review processes that infrastructure teams have historically relied on weren’t designed to catch failures that look like successes.
The answer isn’t to slow down AI adoption. It’s to build the governance layer that makes adoption safe at scale, where constraints are machine-enforced, human reviewers focus on judgment rather than checklist compliance, and the delivery pipeline itself provides accountability rather than assuming it.
That’s what constraint-first infrastructure platforms are for. And as GenAI becomes more deeply embedded in how infrastructure gets built, that governance layer stops being optional and starts being the difference between scaling confidently and scaling dangerously.
Don’t let AI redefine your infrastructure standards by accident. Visit www.quali.com to learn more and try Quali Torque and see what constraint-first automation looks like in practice.