Cloud waste is starting to look insignificant compared to today’s runaway GPU costs. Yet, every business is in a race to grab more GPUs, all underutilized, setting a perfect stage for the next, and bigger, technical debt storm.
Unfortunately, FinOps tools, with their emphasis on post-mortem cost visibility, can’t solve the problem. Cloud waste, and AI debt in particular, is an infrastructure orchestration breakdown, one that cost management dashboards simply aren’t built to solve.
The solution is Infrastructure platform engineering (IPE), an approach that bakes cost control into GPU (and cloud infrastructure) provisioning without Engineering teams having to sweat it out themselves.
Let’s dig into why GPU-driven waste is fast becoming the next technical debt and how IPE fixes it.
Why technical debt from GPU workloads is much worse
GPU-driven cloud waste isn’t just about over-provisioned storage or VMs; it’s about multi-million-dollar GPUs running nearly idle. GPUs are currently the most expensive infrastructure investment, costing 10-50x more than basic cloud resources. That makes GPU-led debt one of the most pressing infrastructure cost sinkholes.
With cloud infrastructure, waste comes largely from over-provisioning and poor control over the pay-as-you-go models that charge per API call or per GB stored. However, waste from AI workloads is a different ball game. Here’s why:
1.GPUs are pre=-allocated: Virtual machines (VMs) and bare-metal nodes are launched with one or more dedicated GPUs pre-reserved. Scheduler-driven orchestrators such as Kubernetes assign an entire GPU to a pod. Now, this GPU pre-allocation presents a critical problem: Most GPU-backed Kubernetes clusters operate at 15-25% utilization, barely touching their potential.
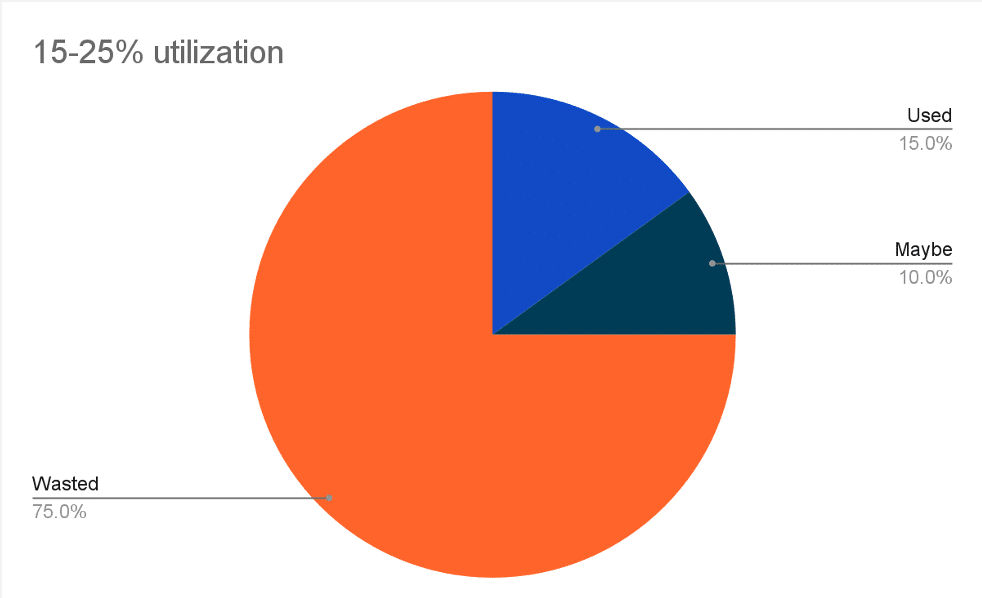
Figure 1: Only between 15-25% of GPU capacity is used in K8s clusters
Data source: https://www.devzero.io/blog/why-your-gpu-cluster-is-idle
The reason for this is because small training and inference workloads are left to monopolize big GPUs. We’re talking about a potential 85% cost surcharge on every GPU provisioned, every training job run, and every inference workload shipped.
Why isn’t anything being done to offload this excess capacity to other workloads? Well something is, but…
2, All the GPU allocation models are proprietary
Mechanisms such as NVIDIA’s multi-instance GPU (MIG) and AMD’s MxGPU partition GPUs to allow sharing. However, they surface interoperability challenges in inter-GPU, inter-cluster, and inter-vendor settings, which turns idle GPU capacity that could be reallocated to active jobs into stranded compute. And just like that, we’re back full circle.
An AI Job on a H100 is wasting GPU cycles? You can’t transfer what’s left to an inference workload running on an A100. So despite getting only 15% of the value, you’re paying for 100% of the GPU, with the technical debt multiplying across tens of workloads and GPU instances.
3. Devs and AI engineers cautiously overprovision GPU
Overprovisioning is another major issue driving the unprecedented AI waste. A substantial bulk of workloads being shipped on massive servers can be run with smaller GPUs or even provider APIs. Yet, teams learning the AI domain frequently overprovision capacity to save headroom for model growth or rising inference needs. Meanwhile, GPU debt quietly balloons in the background.
4. Slow data pipelines and CPU bottlenecks waste GPU cycles
GPU-led waste goes beyond overprovisioned capacity. Rightsized GPU instances also see substantial waste due to bottlenecked data pipelines. So, when you have a training job running on 10 H100 GPUs costing north of $30,000 each, you’re probably paying $150,000-$200,000 for GPUs twiddling their thumbs—an 100-200% tax on AI investments.
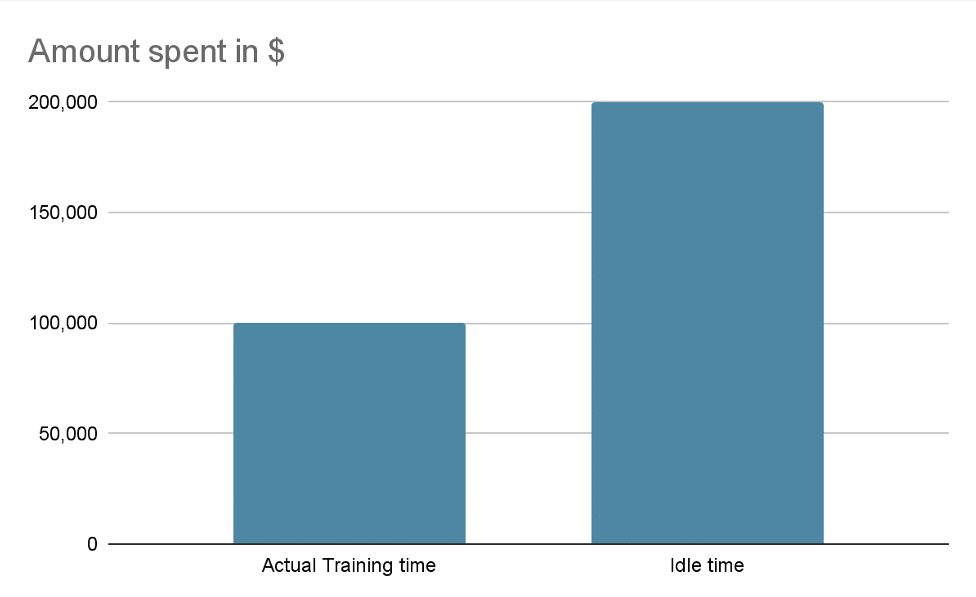
Figure 2: The reality of the huge waste that spirals model training costs out of control
Data source: https://www.alluxio.io/blog/maximize-gpu-utilization-for-model-training?utm_source=chatgpt.com
The reason AI waste has reached these unsustainable levels? IT leads and business decision-makers see figures so vast that they automatically assume it’s someone else’s problem—the waste is so huge and abstract that it couldn’t possibly have come from their own budgets. But, in fact, it has. The breakdown below shows why every C-suite cadre must take action to stop waste immediately.
The daily cost of AI debt
Given the prohibitive cost of GPUs, AI-driven cloud waste builds up very quickly:
A company starts with a few H100s as an experiment, then adds a few more GPUs when it’s decided to customize an in-house model.
In the next phase, experimenting continues so the previous GPU capacity keeps running with new dedicated servers for inference.
Then comes the shock. Quarterly FinOps cost reviews show in vivid detail: The entire year’s IT budget is gone, all spent on GPUs doing little and offering nearly zero returns. Here’s a breakdown of what it looks like:
One NVIDIA H100 server instance costs $30-50 per hour across major cloud providers. Say a mid-market firm spins up 15 training GPUs and 9 inference servers, 24 in total, at $40 per hour, with an average of 25% utilization.
Every hour, the GPUs burn through $960, $720 of which is wasted spend. While that doesn’t look like much, consider that every day, the GPUs rack up $23,040, $17,280 of which goes straight to the drain. The figure is starting to climb, so FinOps dashboards suggest shutting down a few instances.
Engineering takes out two idle training GPUs and calls it a day. But out of the $633,600 bill at month end, $475,200 is still vaporized on idle GPU cycles. Now, the figure gets full attention—after shrinking profit margins beyond repair.
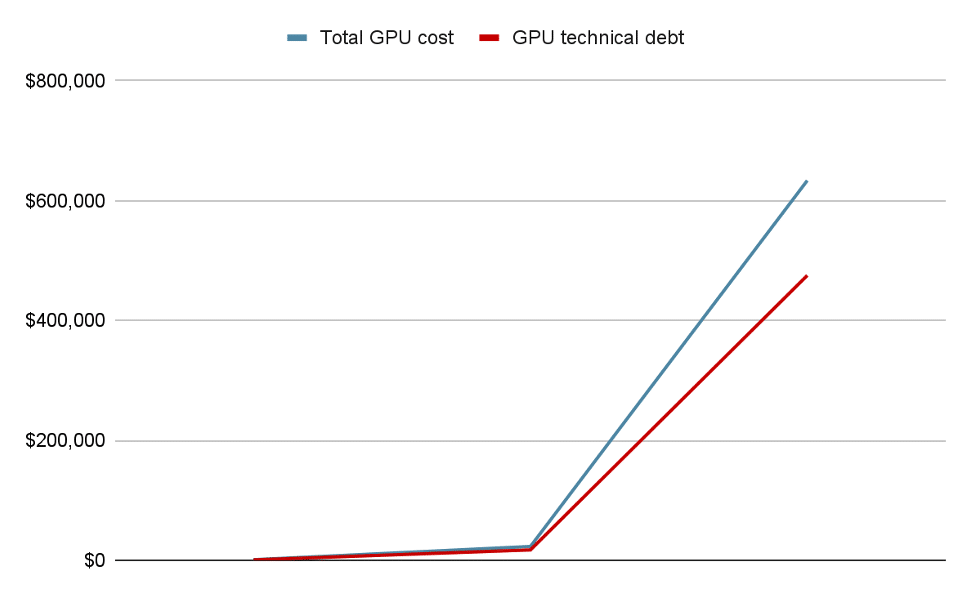
Figure 3: The unit cost of GPU-led waste
When IT leads finally grasp the true scale of the waste in their infrastructure, the natural inclination is to turn to FinOps. But FinOps as it currently stands (framework, tools, and all) is turning out to be more of a financial and operational liability than a solution.
Why stopping AI waste is beyond traditional FinOps tools
FinOps can’t handle GPU-led waste because its approach is diametrically opposed to the reality of AI workloads:
- FinOps tools can’t see the systems creating the waste. It’s impossible for these tools to tell when an oversized GPU is being provisioned or to diagnose waste being compounded by a broken data pipeline.
- Reporting after the fact. While spend visualization is great, no amount of color-coded cost reports can turn the hand of the clock after GPUs have been overprovisioned.
- Agentic workloads spin up too fast for FinOps tools. GenAI agents are designed to act independently, spawning new GPU instances, scaling them beyond budget thresholds, and leaving no trace afterwards.
The extent of the AI debt is often a shock to many businesses using FinOps tools. But what if you could run AI and cloud infrastructure with zero waste, by design?
How platform engineering control planes resolve AI waste instantly
To plug GPU-led debt, cost control must be embedded into the infrastructure foundation—this is where infrastructure platform engineering (IPE) comes in. Unlike FinOps visibility, which begins post-deployment, IPE controls waste by reinventing AI infrastructure orchestration from the very source:
- Out-of-the-box cost management: IPE ensures humans and agentic processes can only spin up AI resources within pre-approved budget limits. This turns GPU waste prevention into a real-time predeployment control function, rather than a reactive assessment process.
- Controlled self-service: IPE systems let AI engineers provision resources on demand, but within the bounds of predefined guardrails. This simultaneously prevents waste and cautious overprovisioning. What’s more? According to McKinsey, self-service portals with built-in budget controls are an essential way to tackle AI-driven waste and other problems sinking GenAI programs.
- Governance from Day 0: The moment a training job or inference workload is created through an IPE’s environment blueprint, the IPE auto-implements the tagging, attribution, instance sizing, scheduling, and resource limits. This provides real-time intelligence into details such as who is deploying what and for what business use case, all of which is critical for enforcing cost control at provisioning.
- Every GPU that’s provisioned has a start/stop date: As GPUs are created, the IPE tags them with expiration dates. If they continue running past these dates, the IPE system will automatically decommission them (if they are idle) or flag them (if active).
- Intelligent provisioning and right-sizing by default: Rather than considering cost as a standalone metric, IPE aligns resource provisioning with business context, making decisions on provisioning, sizing, and decommissioning the business priorities at that time, such as preventing GPU provisioning when CSP APIs would do the job.
- Day-2 lifecycle management with cost as an architectural constant: Rightsized GPU instances can become underutilized if demand suddenly drops. IPE continuously monitors live usage, spots emerging waste, shuts down idle resources, and reallocates excess capacity.
Conclusion: Stop the GPU debt from piling up
GPU workloads are fast exposing an unprecedented wave of technical debt. GPUs, which come at a $30–$50 per-hour premium, are seeing massive underutilization, whether it’s from overprovisioned servers sitting idle, oversized GPUs assigned to tiny workloads, or preallocated instances running wasted cycles due to scheduling and sharing inefficiencies.
FinOps dashboards can spot the waste but they simply aren’t equipped to stop the waste before it happens. IPEs such as Quali Torque can do that.
IPEs can ensure GPUs only see the light of day when they stay within governance and cost guardrails, controlling who spins up an instance, within what budget limits, for what duration, and to what (business) end. These agentic platforms understand every GPU provisioned, while creating, monitoring, scaling, and decommissioning intelligently. It’s a way to effectively architect waste out of AI workloads.
Quali Torque is one of the leading IPE platforms, offering cost-aware self-service provisioning, AI-driven lifecycle management, and real-time optimization.
Watch the demo or start a free trial to see it in action.