On April 29th , Quali announced that Torque delivers enterprise governance and lifecycle management for NVIDIA NemoClaw, the on-premises autonomous AI agent stack built on OpenClaw, Nemotron 3 Super, and NVIDIA OpenShell. That announcement addressed a specific and urgent operational problem: how enterprises govern autonomous AI agent deployments at scale once they move beyond a single team.
On May 5th, Quali announced the next step. Torque now delivers governed infrastructure for the full NVIDIA Nemotron 3 stack, covering NIM microservice inference, NeMo fine-tuning pipelines, and reinforcement learning training environments, across DGX Spark, DGX Station, on-premises GPU clusters, and cloud infrastructure. Taken together, these two announcements in a single week reflect something more significant than individual product updates. They reflect a deliberate and sustained commitment to building the governed infrastructure layer that NVIDIA’s full agentic AI stack requires.
This blog explains what that stack actually is, why governing its full depth is the operational challenge that enterprise AI programs must solve, and what Torque delivers across every layer.
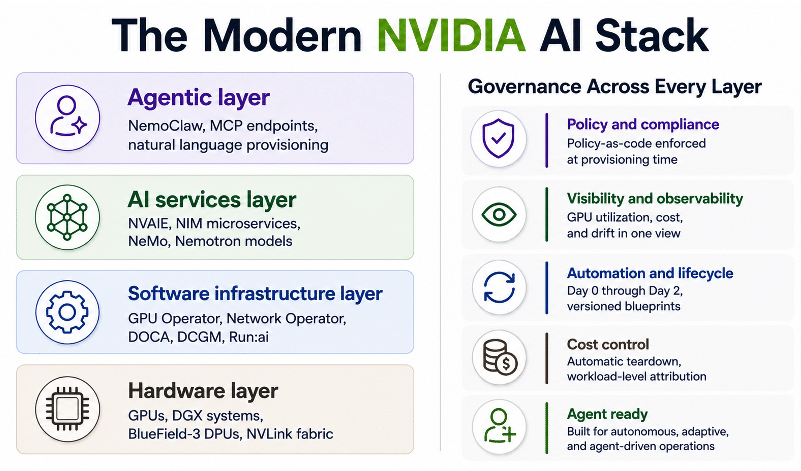
What the Full NVIDIA Agentic AI Stack Actually Looks Like
Most enterprise AI conversations focus on model selection. The more consequential conversation is about what surrounds the model, the inference services, the fine-tuning pipelines, the training infrastructure, and the agent deployment frameworks that turn model capability into operational value. NVIDIA has built all of these layers. Understanding them is essential to understanding why governance across all of them is a non-negotiable production requirement.
- Nemotron 3 is not a single model. It is a family, Nano, Super, and Ultra, covering the full range of enterprise deployment scenarios, from deskside DGX Spark systems to the most demanding multi-agent workloads running on NVIDIA’s Blackwell architecture. Nemotron 3 Super is now generally available. Nemotron 3 Ultra is imminent.
- NVIDIA NIM microservices wrap Nemotron 3 models as containerized, production-grade inference endpoints, integrated with the GPU Operator and NIM Operator, optimized for NVIDIA GPU infrastructure, and deployable as managed services that other applications and agents consume.
- NeMo fine-tuning pipelines give enterprises the tooling to adapt Nemotron 3 models to their own domains, data, and use cases. Fine-tuning runs on GPU infrastructure, consumes significant compute, and produces model artifacts that feed production inference services. It is a distinct operational environment with its own lifecycle, cost profile, and access requirements.
- Reinforcement learning environments take multi-agent AI systems a step further, enabling agents to learn from interaction and feedback at scale. RL training is computationally intensive, team-specific, and requires the same lifecycle controls as any other GPU workload: isolation, cost attribution, and automatic teardown when training runs complete.
- NVIDIA NemoClaw announced, packages OpenClaw, Nemotron 3 Super, and NVIDIA OpenShell into a hardened, on-premises autonomous AI agent stack validated on DGX Spark. It is the deployment blueprint that enterprises use to put Nemotron 3-powered autonomous agents to work securely and at scale.
Each of these is a distinct operational environment. Each requires governance. None of them governs themselves.
Why Governing Each Layer Is a Different Problem
A single NIM inference endpoint for Nemotron 3 Super is a manageable deployment. The moment that endpoint needs to scale to five teams, each running their own fine-tuning pipelines and RL training environments on shared GPU infrastructure, the operational requirements multiply in ways that deployment tooling alone was never designed to handle.
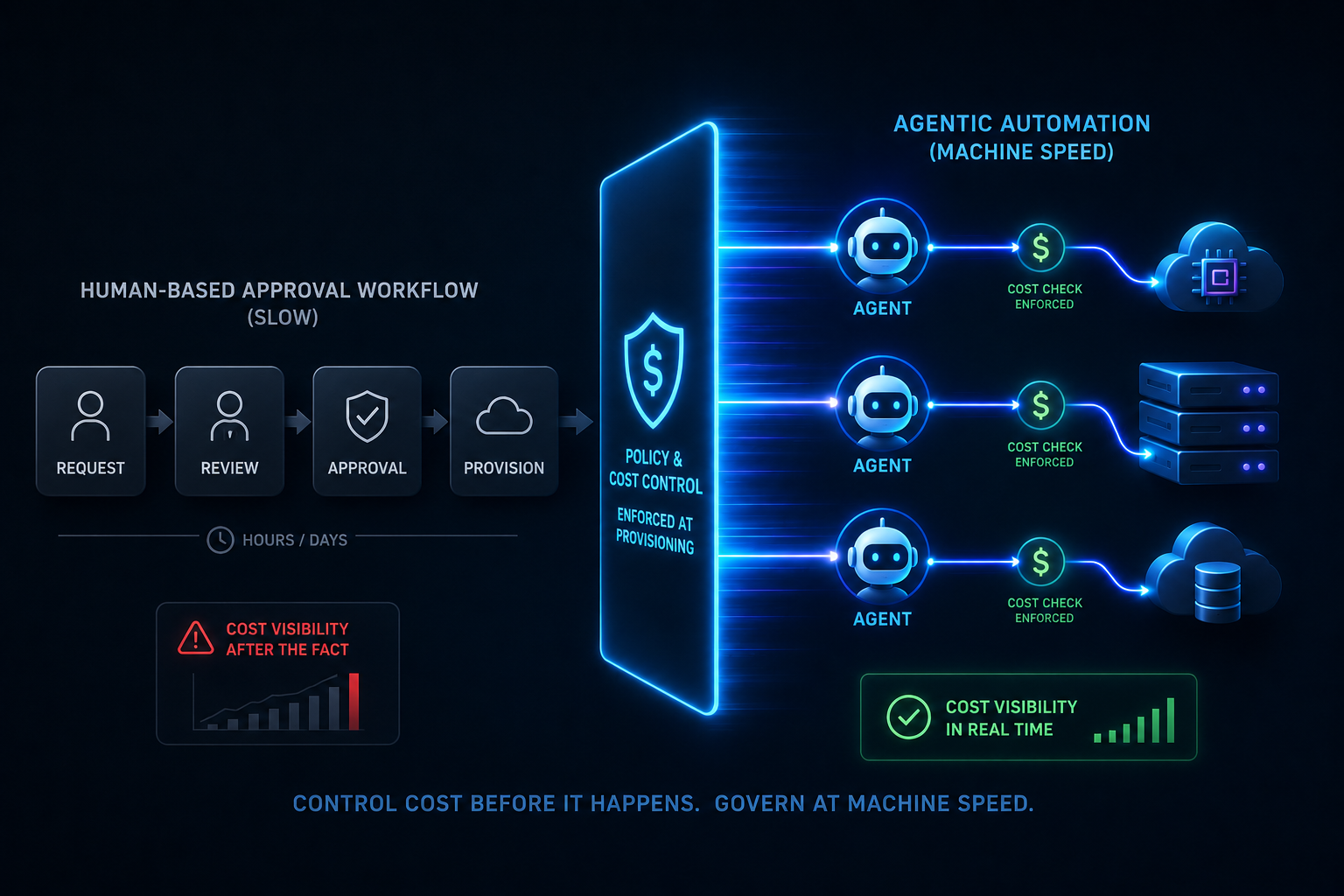
Access governance across every layer and every team. Policy enforcement that is consistent whether a team is running NIM on DGX Spark, NeMo fine-tuning on an on-premises GPU cluster, or RL training on a cloud GPU instance. GPU cost attribution that separates inference spend from training spend, per team and per project. Versioned blueprints that make every environment reproducible and auditable. Automatic teardown when training runs complete, so GPU resources do not continue accumulating cost between jobs. Self-service access for data scientists and ML engineers who should not need to understand infrastructure tooling to do their work.
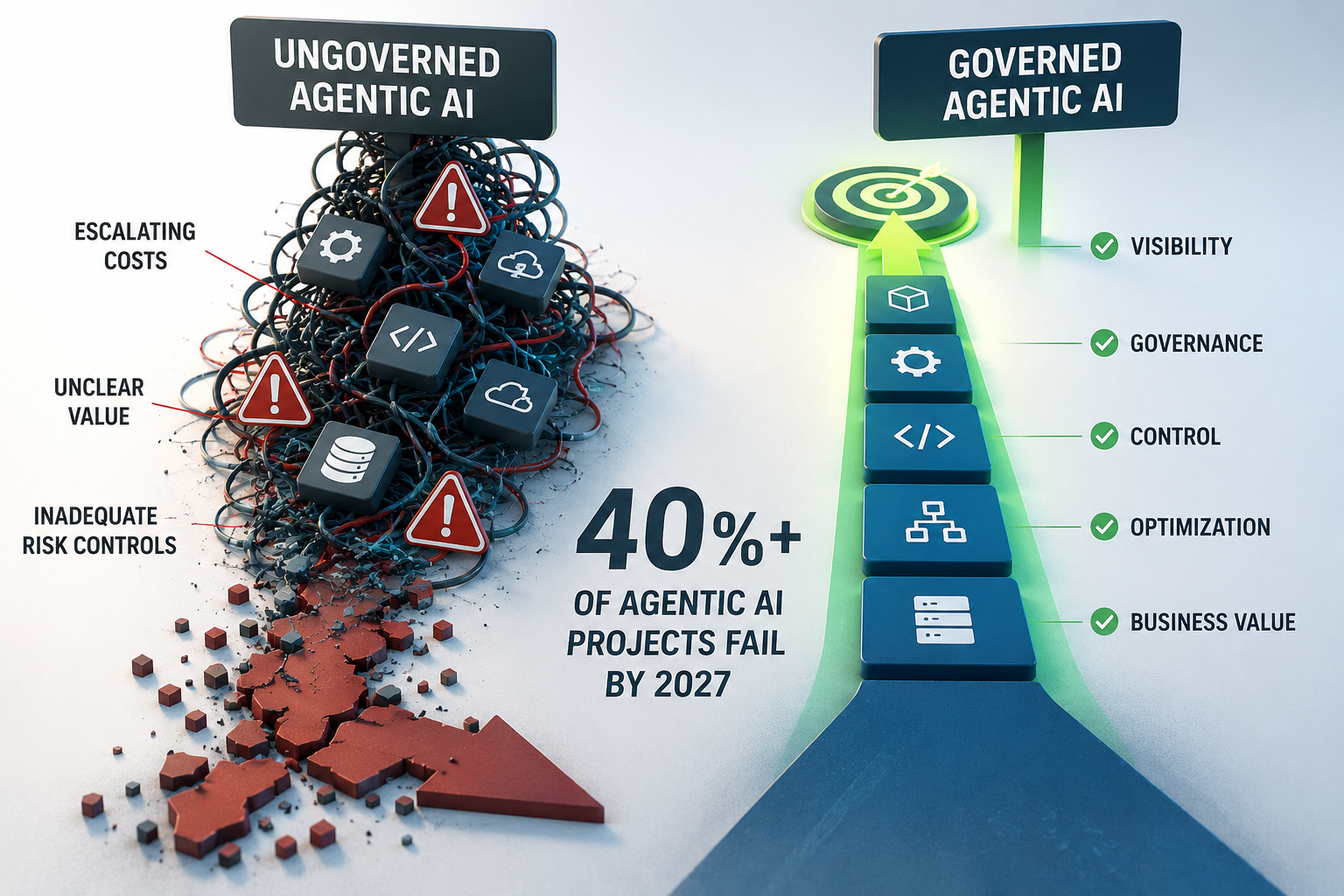
Without a governance layer that spans all of these consistently, organizations face documented and predictable failure modes. The data remains unambiguous.
- 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs, inadequate risk controls, and governance structures that were never put in place. Source: Gartner
- 1 in 5 companies currently has a mature governance model for autonomous AI agents, even as deployment accelerates sharply across the enterprise. Source: Deloitte State of AI in the Enterprise, 2026
The Nemotron 3 stack raises the stakes on this problem because it multiplies the number of distinct operational environments a single AI program requires. NIM inference, NeMo fine-tuning, RL training, and NemoClaw agent deployment are not the same environment. They have different compute profiles, different team access requirements, different cost structures, and different lifecycle patterns.
Managing them separately, manually, and without a unified governance model is not a production strategy. It is a path to the cancellation rate Gartner is already predicting.
What Torque Delivers Across the Full Stack
Torque is the control plane above the full NVIDIA agentic AI stack. It does not replace any component of it. It governs every layer’s operational lifecycle, consistently, under one policy model, across all hardware targets.
Governed NIM Deployment. Torque provisions and lifecycle, manages NVIDIA NIM microservice environments via automated GPU Operator and NIM Operator integration. Teams deploy Nemotron 3 inference services from versioned blueprints, with full policy enforcement and automatic teardown. Every environment is reproducible, auditable, and consistent. No manual configuration. No environment drift.
Governed NeMo Fine-Tuning Environments. Torque provisions NeMo fine-tuning environments on demand, enforces policy on GPU resource consumption, and automatically tears down environments when training runs complete. GPU costs are attributed per team and per project. Fine-tuning pipelines run consistently across hardware targets without requiring ML engineers to manage the infrastructure beneath them.
Governed RL Training Infrastructure. Torque manages reinforcement learning training environments with the same lifecycle controls applied to inference and fine-tuning. Versioned blueprints. Hard isolation between teams. GPU cost attribution. Automatic teardown. RL environments do not idle between training runs, consuming GPU budget that should be available to other workloads.
Governed NemoClaw Agent Deployment. Torque provisions and lifecycle-manages the full NemoClaw stack, Nemotron 3 Super model serving, OpenClaw gateway configuration, and NVIDIA OpenShell sandboxing, as governed, multi-tenant environments. Policy enforcement, team isolation, and automatic teardown apply to agent workloads exactly as they do to inference and training workloads.
Self-Service for Every AI Team. Data scientists, ML engineers, developers, and operations teams access governed environments on demand through Torque’s self-service portal. No IT tickets. No infrastructure expertise required. Cost attribution and compliance controls are built in from the first environment provisioned, not retrofitted after costs become unmanageable.
One Control Plane Across All Hardware. The same Torque blueprints and governance policies that manage workloads on NVIDIA DGX Spark and DGX Station scale seamlessly to on-premises GPU clusters and cloud infrastructure. One governance model. One operational standard. Every layer of the stack. Every hardware target.
What The Two Quali Announcements Mean
The NemoClaw and Nemotron 3 announcement reflect the same strategic reality. Enterprises building on NVIDIA’s agentic AI stack need governance that covers the entire stack, not individual components. Each announcement extends Torque’s coverage to another layer. Together, they deliver something that no other platform provides, a single, governed control plane for the full NVIDIA agentic AI estate.
Torque is now validated across NVIDIA DGX Spark, DGX Station, GPU Operator, NIM Operator, NemoClaw, and the complete Nemotron 3 model family from Nano through Ultra. Quali is among the earliest software partners to validate Torque on NVIDIA’s Blackwell architecture. That breadth is the result of deliberate investment in NVIDIA’s ecosystem, and it means enterprises do not need separate governance solutions for inference, fine-tuning, agent deployment, and hardware. Torque handles all of it.
- 93% of IT leaders plan to introduce autonomous agents within two years, with nearly half already having done so. Source: 2025 Connectivity Benchmark Report, MuleSoft and Deloitte Digital
For enterprises at the point of committing to NVIDIA’s agentic AI stack, the question is not just which components to deploy. It is whether those components will be governable, accountable, and scalable as the program grows from one team to the entire organization. That is the question Torque was built to answer.
A Complete, Governed AI Infrastructure Stack
Until now, no platform governed the full NVIDIA agentic AI stack end to end. Torque does.
NIM inference. NeMo fine-tuning. Reinforcement learning training. NemoClaw autonomous agent deployment. DGX Spark. DGX Station. On-premises GPU clusters. Cloud infrastructure. One control plane. One governance model. Production-ready from day one.
For IT and infrastructure leaders building out an AI stack that is meant to last, and meant to scale, this is what leading AI infrastructure management looks like in practice.
NemoClaw press release: Quali’s Torque Platform Brings Enterprise Governance to NVIDIA NemoClaw
Nemotron 3 press release: Quali’s Torque Platform Extends NVIDIA Ecosystem Support to Nemotron 3
Read the previous blog: Managing Autonomous AI Agents at Enterprise Scale Is Now a Business Imperative
To see Torque in action, visit the Torque playground, or book a live demo to see how Torque is a major contributor to address the risks caused by agentic agent conflict.