Run Large Language Models as a Governed Service — Every Time
Torque provisions the complete LLM stack, GPU layer, runtime, model weights, and dependencies, as one governed blueprint, identically, every time
Is Your LLM Infrastructure Reproducible
or Just Occasionally Working?
A model that behaves differently between runs is not a reliable system. It is a configuration problem.

Assembly Is Manual Every Time
GPU layer, runtime, model weights, and dependencies assembled by hand take hours and drift between runs. No two deployments are guaranteed to be identical.

Environments Diverge
Without identical governed environments at every stage, what ran in development does not reliably run in production. Reproducibility is assumed, not guaranteed.

Cost Is Structurally Unpredictable
Models overrun. Inference environments sit idle between requests. GPU costs spike without warning. Monthly reviews are the wrong instrument for this problem.
Torque provisions the complete LLM stack as one governed blueprint.
Every Layer. Every Time
GPU compute, inference runtime, model weights, frameworks, and configuration provisioned together as a single governed blueprint, in the correct order, with the correct dependencies, identically every time. What used to take hours of manual assembly takes minutes and never drifts
Identical Environments Across Every Stage
Training and production environments provisioned from the same governed blueprint. What ran in development is exactly what runs in production. Reproducibility is not assumed or hoped for. It is structural.
Cost Controlled Before the Model Runs
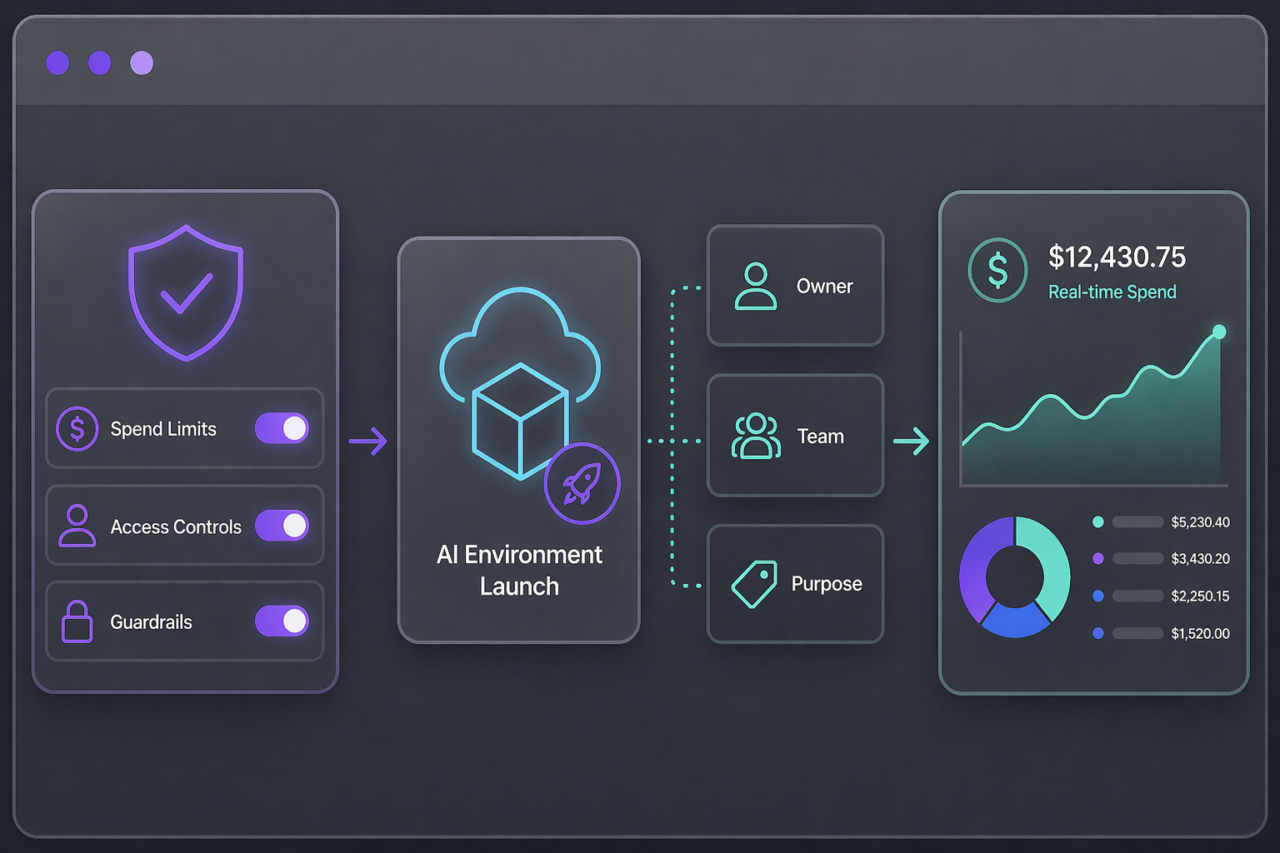
Spend limits enforced at provisioning before any GPU environment launches. Inference environments scaled with demand and shut down automatically when idle. The most expensive workloads in the organization governed with the same controls as everything else.
Torque provisions governed LLM infrastructure as a complete stack
Define the complete LLM stack as a governed blueprint
GPU resources, inference runtime, model weights, frameworks, and configuration defined together. Every component versioned. Every dependency captured. The full stack in one place, ready to provision identically every time.
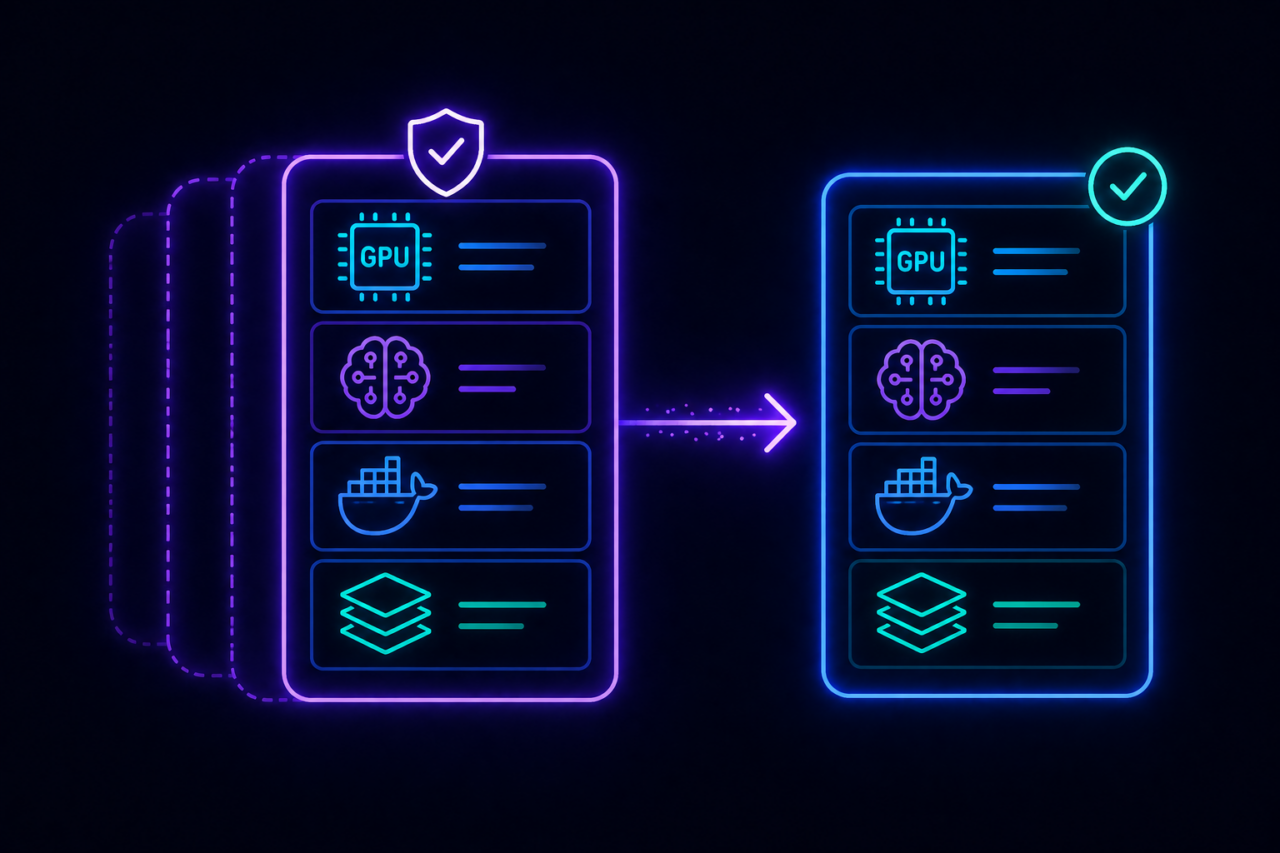
Anyone can request an LLM environment — no skills required
Describe the model and workload requirements in plain language. Torque matches the request to the right governed blueprint and provisions every layer simultaneously. No infrastructure expertise. No manual assembly. No ops handoff.
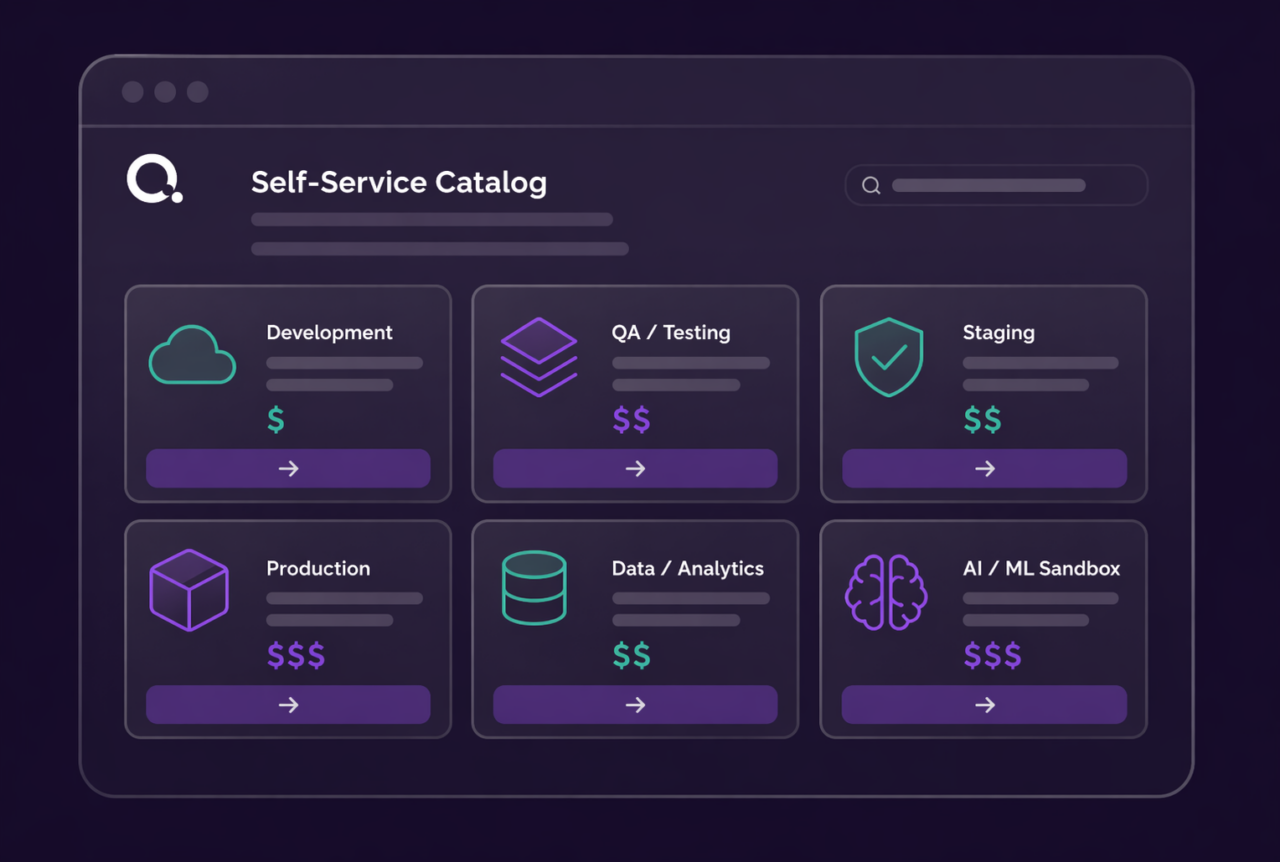
Enforce consistency across every stage
Training and production environments provisioned from the same governed blueprint. What runs in development is exactly what runs in production. Reproducibility is structural and verifiable, not assumed.
Monitor for drift, control cost throughout the lifecycle
Every running LLM environment monitored against its governed blueprint. Configuration deviations detected before they reach production. Inference environments scaled with demand and shut down automatically when idle. Nothing runs longer than it should.
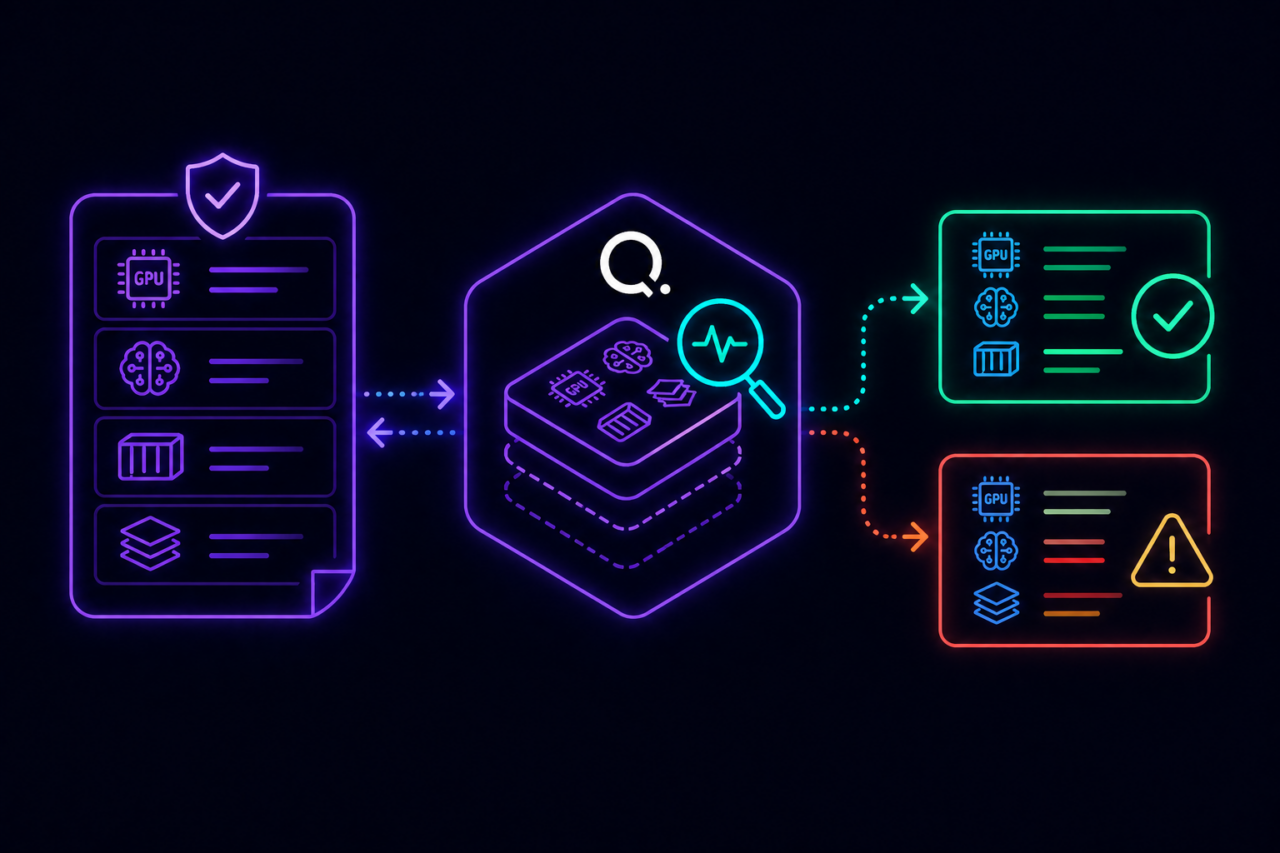
Attribute cost, optimize against priority
Every LLM environment tagged at creation with owner, team, model, and business purpose. Spend limits enforced before launch. When capacity is constrained, lower-priority workloads yield to higher-priority ones. The most expensive workloads in the organization governed like everything else.
Supported Ecosystems
Models & Runtimes:
NVIDIA NIM | NeMo | LLaMA | Mistral
Infrastructure:
AWS | Azure | GCP | VMware
Orchestration:
Kubernetes | GPU Platforms
Automation:
REST API | CLI
Watch a Demo to See How Torque in Action
Delivering the AI Stack

Value & Impact
1.
Complete LLM stack provisioned in minutes, not hours
2.
Training and production environments identical across every run
3.
Reproducibility guaranteed through governed, version-controlled blueprints
4.
LLM infrastructure cost controlled before the model runs
5.
Full visibility into execution, utilization, and cost
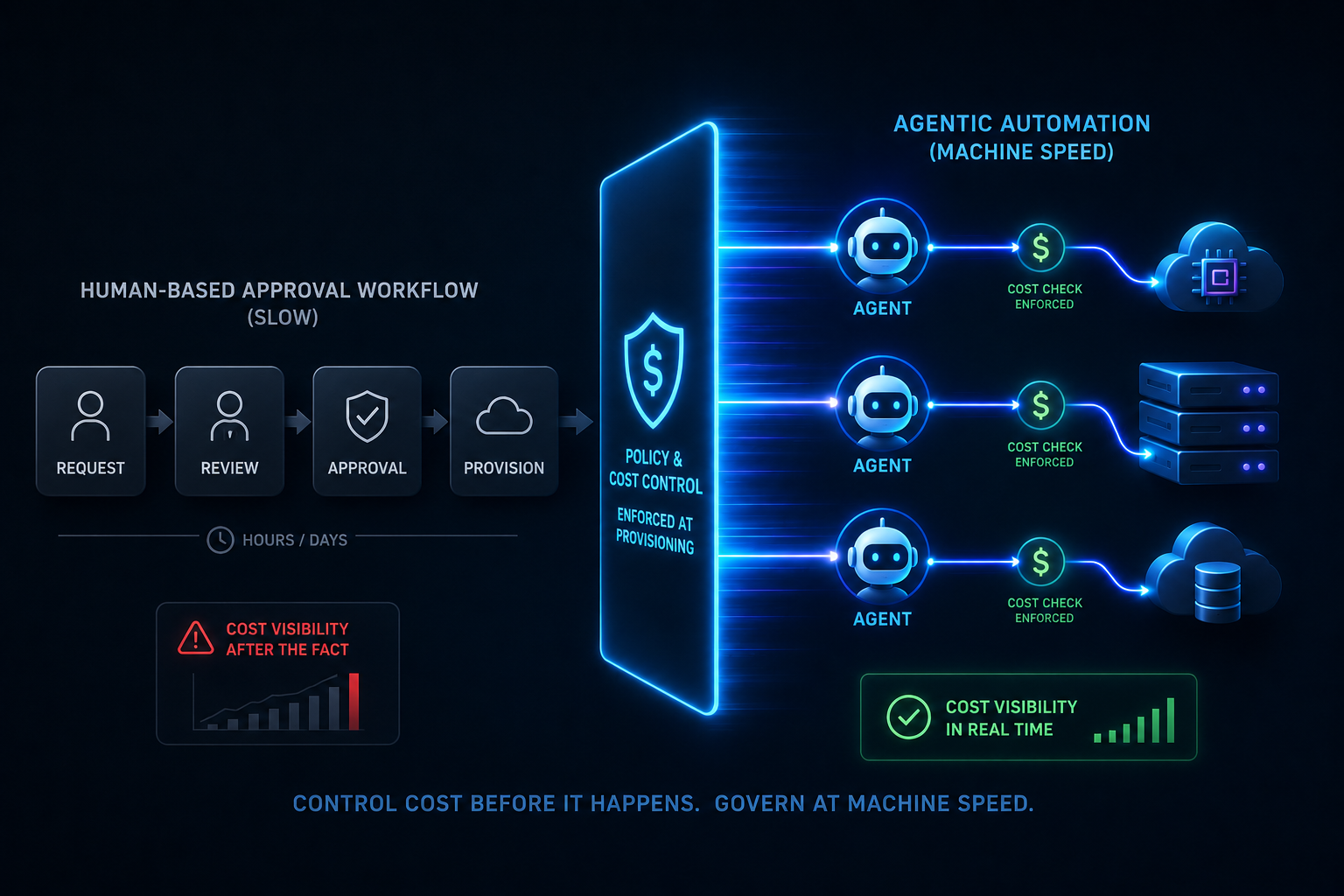
Try it yourself
Explore Torque in a live playground
No installation. No configuration. Launch a fully governed environment in minutes and see how Torque discovers, normalizes, and controls infrastructure across your technology stack.
Pre-loaded blueprints across IaC, containers, and GPU infrastructure, ready to launch in one click.
Real governed environments that provision, enforce policy, and tear down automatically.
No credentials required, explore the full platform experience without connecting your own cloud.
Live cost and drift tracking so you can see the governance layer in action from day one.
Want to understand how Torque can transform your business?
Talk to our team and see what governed infrastructure looks like in your environment.