Your Models Are Ready. Your Infrastructure Should Be Too.
Torque gives you instant access to the GPU infrastructure, AI services, and compute environments your work needs, without writing a line of infrastructure code, raising a request, or waiting on anyone else. Just describe what you need. Torque handles the rest.
Stop Waiting for Compute.
Start Building What Matters.
Torque removes the gap between what your models need and what you can actually get your hands on, giving you on-demand access to the right GPU infrastructure, with everything configured, governed, and ready to run the moment you need it.

The Infrastructure You Need Is Never Just There
Getting GPU resources, AI services, and the right compute environment shouldn't require infrastructure expertise or a queue of approvals. But for most data scientists, that's exactly what it takes, and every hour spent waiting is an hour not spent on the work that actually matters.

GPU Time Is Too Valuable to Waste
With GPU costs rising and availability tighter than ever, idle compute is money no one can afford. But without visibility into what’s available, what’s running, and what’s sitting unused, optimizing your GPU usage is nearly impossible, especially when you’re focused on building models, not managing infrastructure.

Your Work Outpaces the Processes Around It
AI moves fast. The approval workflows, access requests, and provisioning processes most organizations still use were built for a different era. By the time infrastructure is ready, your model requirements may have already changed. You need infrastructure that responds at the speed you work.
Torque gives you on-demand access to the GPU infrastructure and AI environments your work needs, without infrastructure expertise, requests, or waiting.
The right compute, instantly, GPU environments provisioned to your exact requirements in minutes, not days.
No infrastructure knowledge required, describe what you need, Torque builds it, configured and ready to run.
No wasted GPU time, environments scale with your workload and shut down automatically when the job completes.
Torque Gives Data Scientists the Infrastructure Control They’ve Never Had Before
From a single platform, you can see what’s available, request exactly what you need in plain language, launch fully configured AI environments in minutes, and keep your work running efficiently, all without touching infrastructure code or depending on anyone else to make it happen.
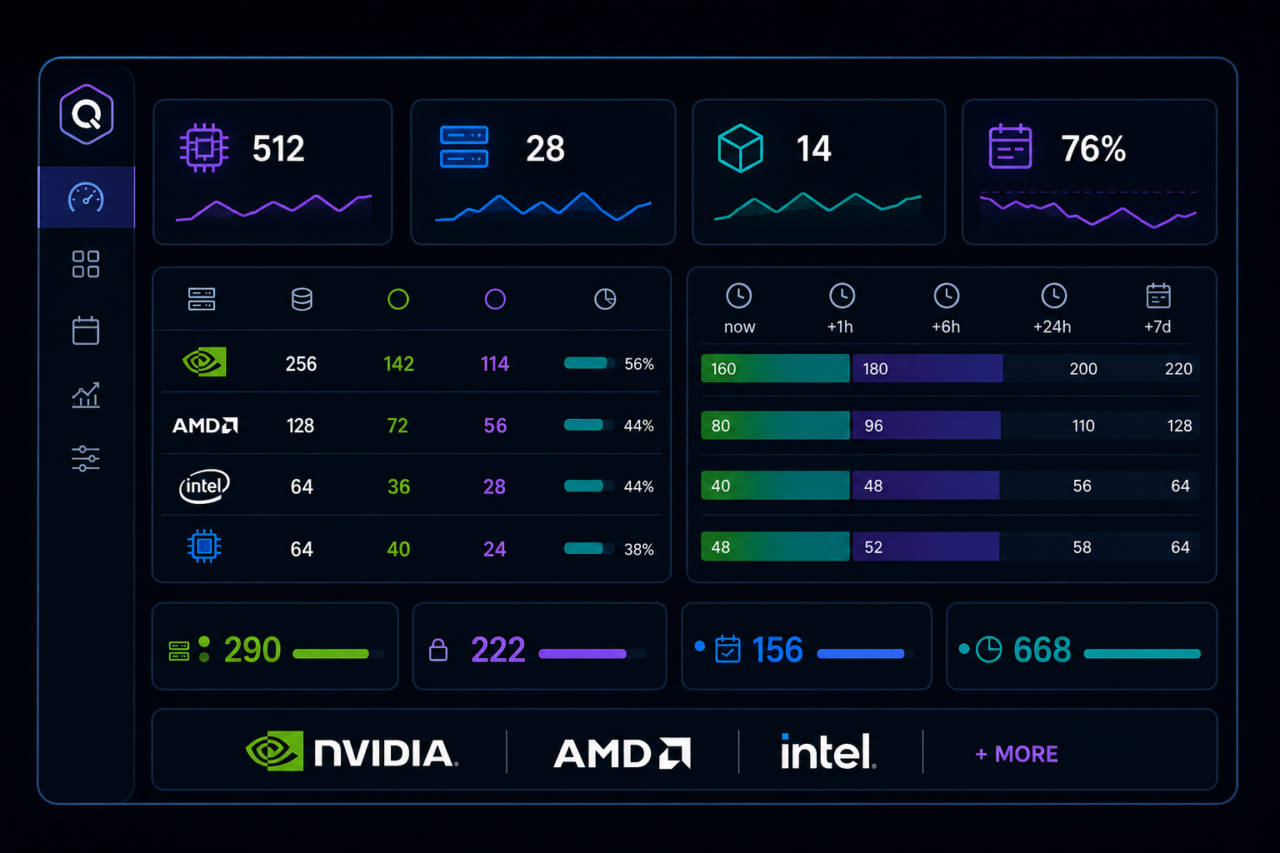
See Everything That’s Available to You
Torque gives you a complete, real-time view of your entire AI infrastructure, GPUs, compute clusters, AI services, and available capacity across NVIDIA, AMD, and other hardware. You always know what’s available right now, what’s reserved, and what you can book ahead. No guessing. No chasing. You can’t plan your work around infrastructure you can’t see. Now you can see all of it.
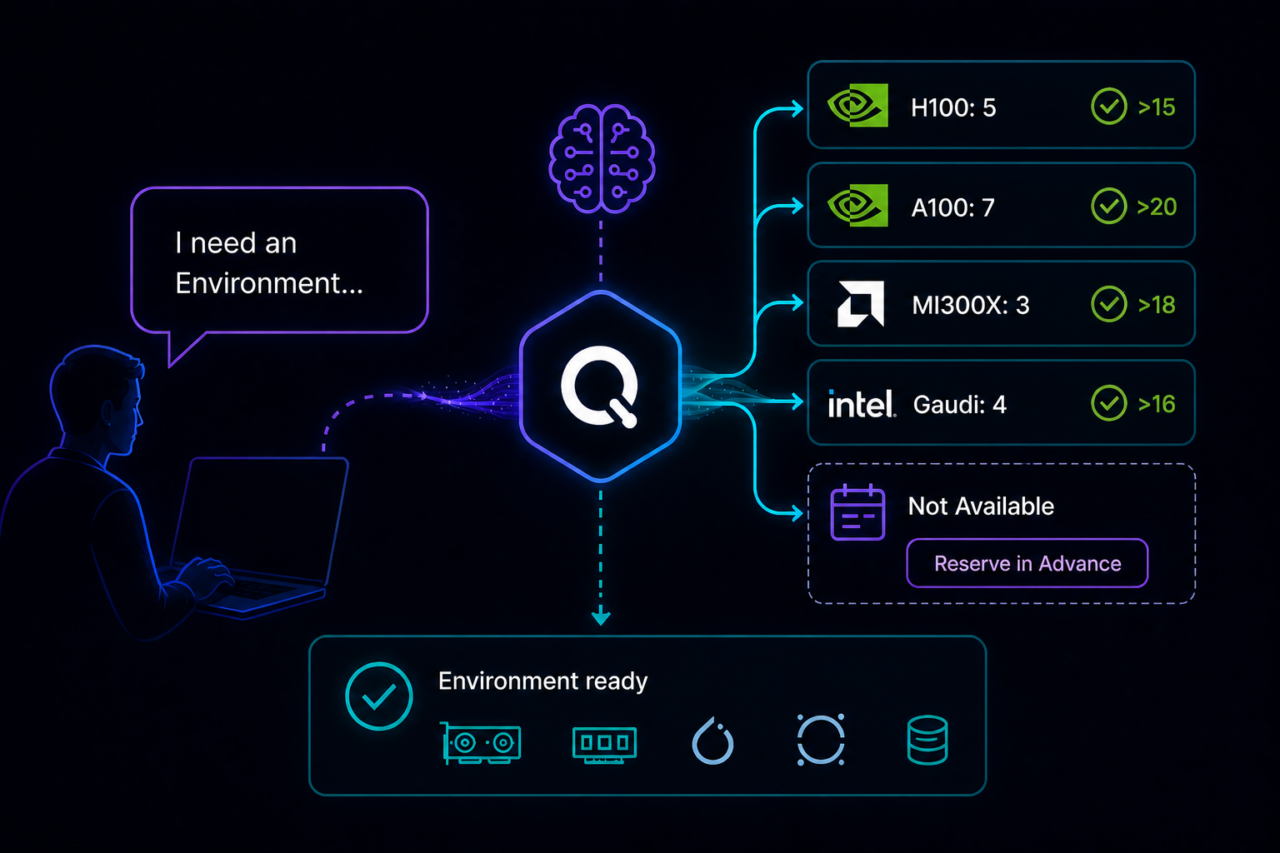
Request What You Need in Plain Language
Describe the environment you need, the GPU type, the memory, the services, the configuration, in plain language. Torque’s AI understands what you’e asking for, matches it to what’s available, and builds it. If what you need isn’t available right now, Torque tells you when it will be and lets you reserve it in advance. No infrastructure knowledge required. No forms, no code, no waiting on someone else to interpret your request.
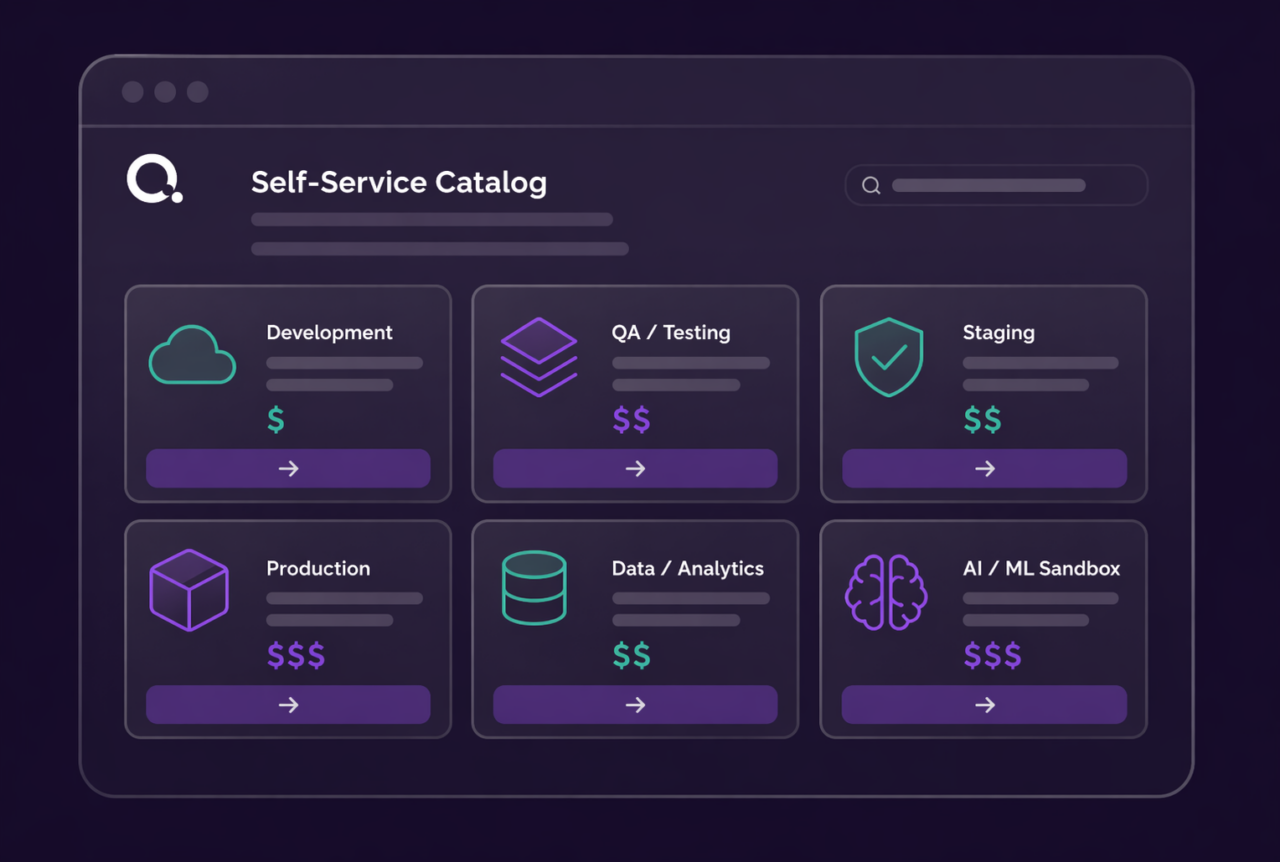
Launch Fully Configured AI Environments Instantly
Whether you’re starting from the self-service catalog, customizing an existing environment, or building something new from a prompt, every environment launches pre-configured with the GPU resources, AI services, storage, and access controls your work requires. NVIDIA NIM, NeMo, and other AI services are part of the stack, ready to go. The environment is built around what your model actually needs, not what was easiest to provision.
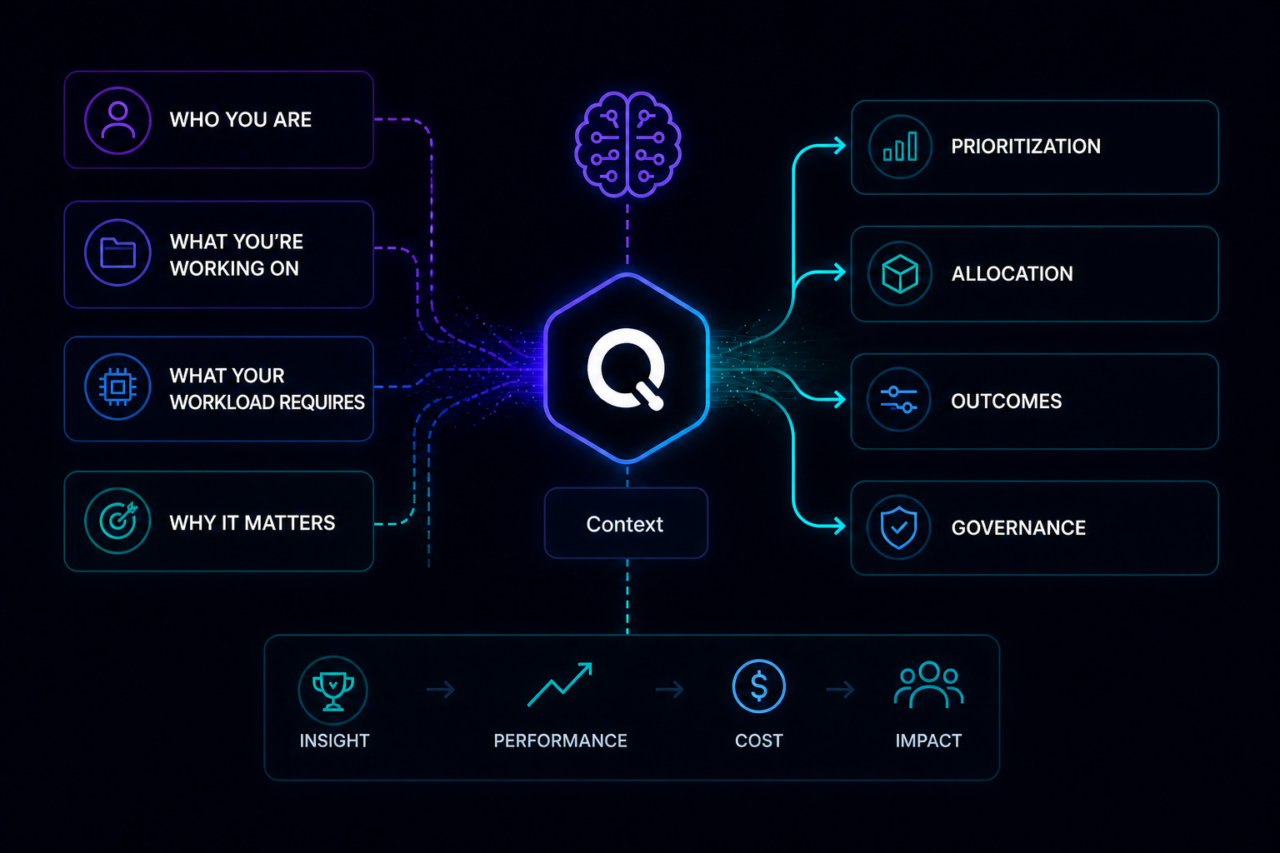
Torque Understands the Context of Your Work
Unlike any other infrastructure platform, Torque understands context, who you are, what you’re working on, what your workload requires, and why it matters to the business. That context drives intelligent prioritization, smarter resource allocation, and infrastructure decisions that align with your outcomes rather than just your request. Your infrastructure isn’t just provisioned. It’s aligned to what you’re actually trying to achieve.
Your Infrastructure Looks After Itself
Torque monitors every environment continuously, tracking GPU utilization, cost, configuration state, and workload performance. When your model needs more capacity, Torque scales it. When a training run finishes, the environment cleans itself up. You always know what’s running, what it's costing, and what’s available next. GPU time is too expensive to waste. Torque makes sure none of it goes to waste.
See How Torque Supports Full-Stack AI Development

Frequently Asked Questions
Without Torque, data scientists who need to access, modify, or update the AI models or Machine Learning services are often required to submit a ticket to an IT, DevOps, or other team that controls access.
This creates an operational bottleneck that can slow down critical operational workflows for data scientists.
To resolve this bottleneck, Torque integrates with NVIDIA AI Enterprise and other AI tools to create, deploy, and monitor custom environments supporting the user’s specific AI and ML services.
With the environment managed as code, Torque can distribute self-service access for data scientists to access the outputs of the AI service on demand. Meanwhile, the IT and DevOps teams responsible for maintaining the environment can set custom policies, automate routine actions, enforce role-based permissions on access to models, and receive notifications about unexpected issues with the environment.
Also, once an AI service is deployed via Torque, the platform enables data scientists to “publish” it so that other groups can access it. For example, the infrastructure engineers maintaining GPU clusters and databases supporting the AI model can access the live environment to test and validate that their infrastructure and data are working correctly, while the developer building an AI agent or application can integrate the live model into their build.
This combination of self-service experience, collaboration, and governance helps to accelerate velocity for teams building AI agents while also preventing security and cost risk.
Torque is agnostic to the types of services, but some examples that our customers have used include:
- GPT-2 Large
- DeepSeek-R1
- Llama-3.2-1b
- Phi-2
- Mistsral-7b-Instruct
- Weaviate
- Spark
- Falcon-40b
Torque defines the custom code to launch the service, provides access to the outputs of the service, and makes it all available to data scientists via an intuitive self-service experience.
Other teams, such as development teams building AI agents or applications, can also access these services when provisioning their unique workloads. This makes access to AI services a seamless part of the development and management of the AI solution.
Yes! Torque leverages your unique NVAIE resources, allows data scientists and others to provision and access the outputs, monitors the state of these resources continuously to identify configuration drift or other unexpected issues, and automatically scales GPU allocation as your AI services transition through various phases of the lifecycle.
Browse Documentation on Torque’s Support for AI Workloads





Try it yourself
Explore Torque in a live playground
No installation. No configuration. Launch a fully governed environment in minutes and see how Torque discovers, normalizes, and controls infrastructure across your technology stack.
Pre-loaded blueprints across IaC, containers, and GPU infrastructure, ready to launch in one click.
Real governed environments that provision, enforce policy, and tear down automatically.
No credentials required, explore the full platform experience without connecting your own cloud.
Live cost and drift tracking so you can see the governance layer in action from day one.
Ready to see more? Book a demo with our team
See how Torque governs your entire technology stack, from IaC to GPU infrastructure, in a live session tailored to your environment.