
Why the organizations pulling ahead on reliability aren’t buying smarter monitoring, they’re governing the infrastructure layer first
There is a version of the AI in operations story that engineering leaders are hearing constantly right now. It goes like this: AI will dramatically accelerate your development velocity. Your systems will become more complex, faster. Your current operations model, built for a slower rate of change, will not keep pace. Therefore, invest in AI-powered observability and incident management to handle the volume.
That story is not wrong. But it is incomplete in a way that leads to the wrong investment decision.
The organizations that are genuinely pulling ahead on reliability right now are not primarily buying smarter monitoring. They are governing the infrastructure layer, and discovering that when you do that properly, a significant fraction of the incidents that would have required smarter monitoring to detect never occur in the first place.
That distinction is worth spending time on, because the capital allocation implications are substantial.
What monitoring actually assumes
Every observability platform, however sophisticated, however AI-augmented, is built on a foundational assumption: that the infrastructure layer below it is in an unknown state. You don’t know whether what is running in production matches what was intended. You don’t know whether a configuration drifted three days ago and nobody noticed. You don’t know whether the environment your developers spun up for a hotfix is compliant, oversized, or still running six weeks later in the wrong region.
Because that state is unknown, you instrument everything, watch for anomalies, and alert humans when something looks wrong. The smarter the monitoring, the better it is at distinguishing real signals from noise, but the fundamental posture is reactive. Something has already gone wrong by the time the system tells you about it.
Industry data makes the cost of this posture visible. High-impact outages now cost organizations around $2 million per hour. The median annual cost of unplanned downtime is approximately $76 million. And, critically, research consistently shows that 35 to 45 percent of production incidents trace directly to infrastructure that had deviated from its intended configuration. Not novel failures. Not edge cases. Configuration drift that nobody caught because nobody had a reliable view of intended versus actual state.
That is not a monitoring problem. That is a governance problem. And monitoring, however intelligent, cannot solve a governance problem.
The layer that changes the economics
The alternative posture starts one layer lower. Instead of watching an unmanaged infrastructure estate for signs of trouble, you treat environments as governed, versioned artefacts, the same discipline that software engineering applied to code a decade ago with version control and CI/CD.
When every environment has a declared intended state, deviations are detectable the moment they occur, not when they manifest as user-visible failures. When provisioning happens within policy guardrails, the questions that currently generate security review tickets (“is this compliant?”, “is this in an approved region?”, “who authorized this instance type?”) are answered before the environment exists, not after. When lifecycle management is automated, the forgotten sandbox running in the wrong region at enterprise-grade cost gets torn down on schedule, not discovered in a quarterly cloud bill review.
The business case for this model is not primarily about technology. It is about where engineering time goes.
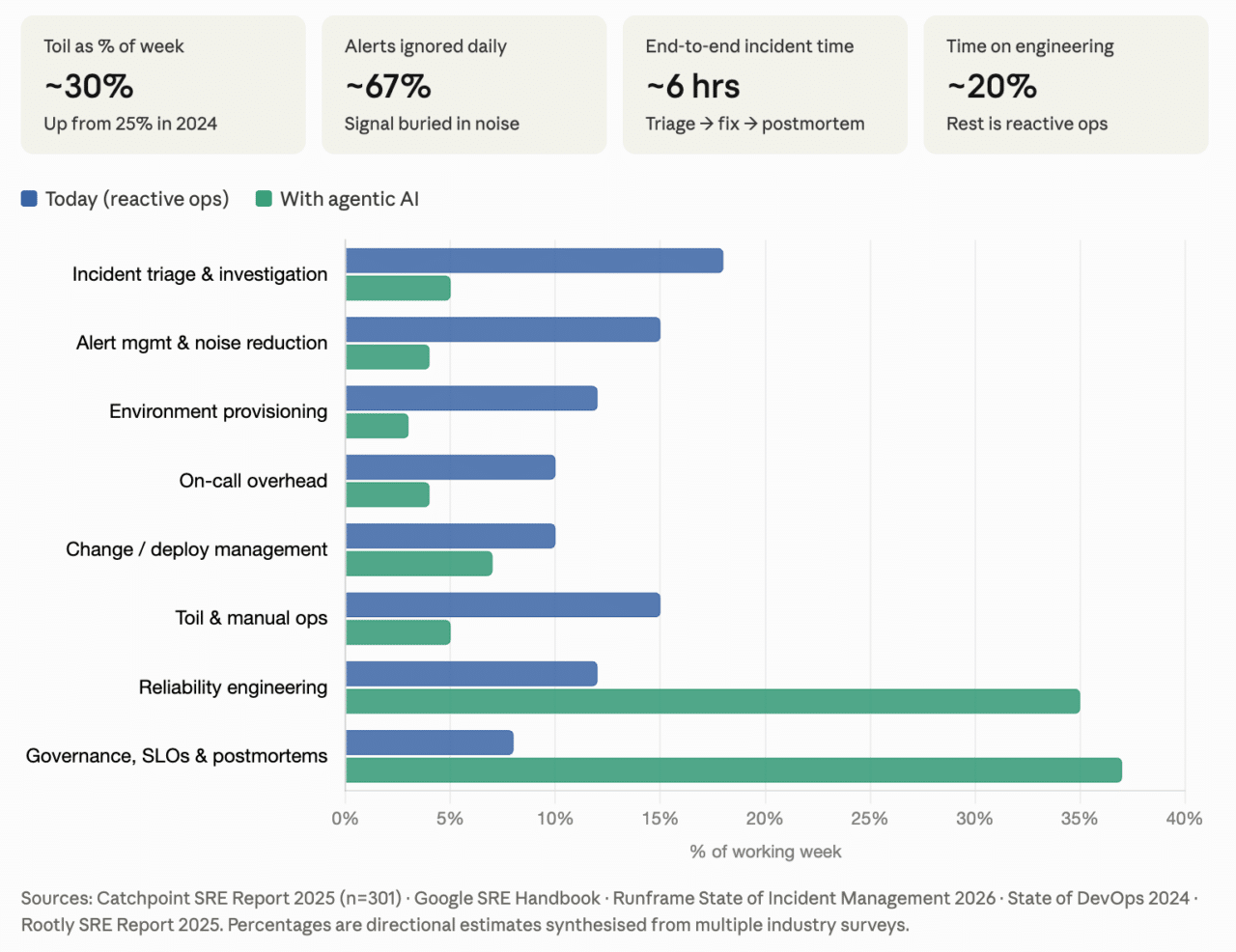
The average SRE today spends roughly 30% of their time on toil, work that is manual, repetitive, and produces no lasting value. A significant fraction of that toil traces to environments that were never properly governed.
The average SRE today spends roughly 30% of their time on toil, manual, repetitive work that produces no lasting value. A significant portion of that toil is environmental: spinning up copies of production for hotfix tests, investigating why a service lost permissions it should never have been able to lose, tracking down who launched oversized instances in the wrong region. These are not engineering problems. They are management-layer problems. The systems are doing what they were told. The issue is that nobody is governing what they are being told.
When the management layer works, when environments are governed artefacts rather than ad hoc outputs of whoever last ran a script. that category of work largely disappears. Not because the SRE became more efficient at doing it. Because it stops existing.
Where agentic AI fits into this
The conversation about agentic AI in operations tends to focus on incident response: autonomous agents that triage alerts, assemble diagnoses, and execute remediation. That capability is real and the numbers are compelling, production deployments are showing 40 to 70 percent reductions in mean time to resolution.
But there is a more important question that this framing obscures: what does the agent reason over?
An agentic system is only as intelligent as the environment model it has access to. An agent operating on top of an unmanaged infrastructure estate can correlate signals and generate hypotheses, but it cannot tell you whether the environment it is reasoning about matches its intended configuration, because no intended configuration has been declared. It can restart a failing pod, but it cannot tell you whether that pod’s configuration drifted from its blueprint three days ago, because there is no blueprint to compare against.
This is the architectural dependency that most discussions of agentic AI in operations miss. The agent needs a queryable, authoritative model of environment state, what should be running, what is running, what changed, and when, to operate at its ceiling. Without that foundation, the agent is a sophisticated script. With it, the agent becomes genuinely capable of autonomous reasoning about your infrastructure.

Value is migrating down the stack. Agentic systems are only as capable as the governance layer they reason over. The organizations building that layer now are the ones whose agents will actually work.
The organizations that are investing in both, governance layer first, agentic operations on top, are the ones whose AI investments will compound. Those who are adding agentic capabilities on top of an unmanaged estate will get incremental gains and continued structural toil.
What this looks like in practice
Quali’s Torque platform is built on the premise that this architectural bet is the right one. It operates at the environment layer, treating environments as governed, versioned blueprints built on your existing IaC, clouds, and tools, and provides the agentic capabilities that depend on that foundation.
For engineering leaders, the operational change looks like this:
The developer who needs a production copy for a hotfix test doesn’t raise a ticket. They launch it from a self-service portal, from a blueprint the platform team defined once, within policy guardrails that ensure it is compliant and scheduled for teardown. The SRE is not involved.
The “why did this service lose its KMS permissions” investigation has an answer in the audit log — a drift event, timestamped, showing exactly what changed and whether it was a deployment or a manual modification outside Git. Mean time to understand drops from forty-five minutes to seconds.
The quarterly cloud cost surprise becomes a continuous signal. Idle environments, over-provisioned resources, and high-cost region mismatches surface in real time with specific remediation recommendations, not in a retrospective review when the damage is already done.
And when an incident does occur, the agentic layer has something to reason over. The intended state of the environment is declared. The change history is complete. The blast radius is calculable. The diagnosis arrives before the on-call engineer finishes reading the alert.
The compounding advantage
The organizations that govern the infrastructure layer now are building a compound advantage. Every blueprint defined is an environment that will never drift silently. Every policy encoded is a security review that will never generate a ticket. Every lifecycle rule set is a cost that will never accumulate unnoticed.
More importantly, they are building the foundation that makes agentic AI genuinely useful rather than marginally helpful. The gap between an agent operating on a governed infrastructure estate and one operating on an unmanaged one is not a feature gap. It is a reasoning gap. One can act intelligently. The other can only react.
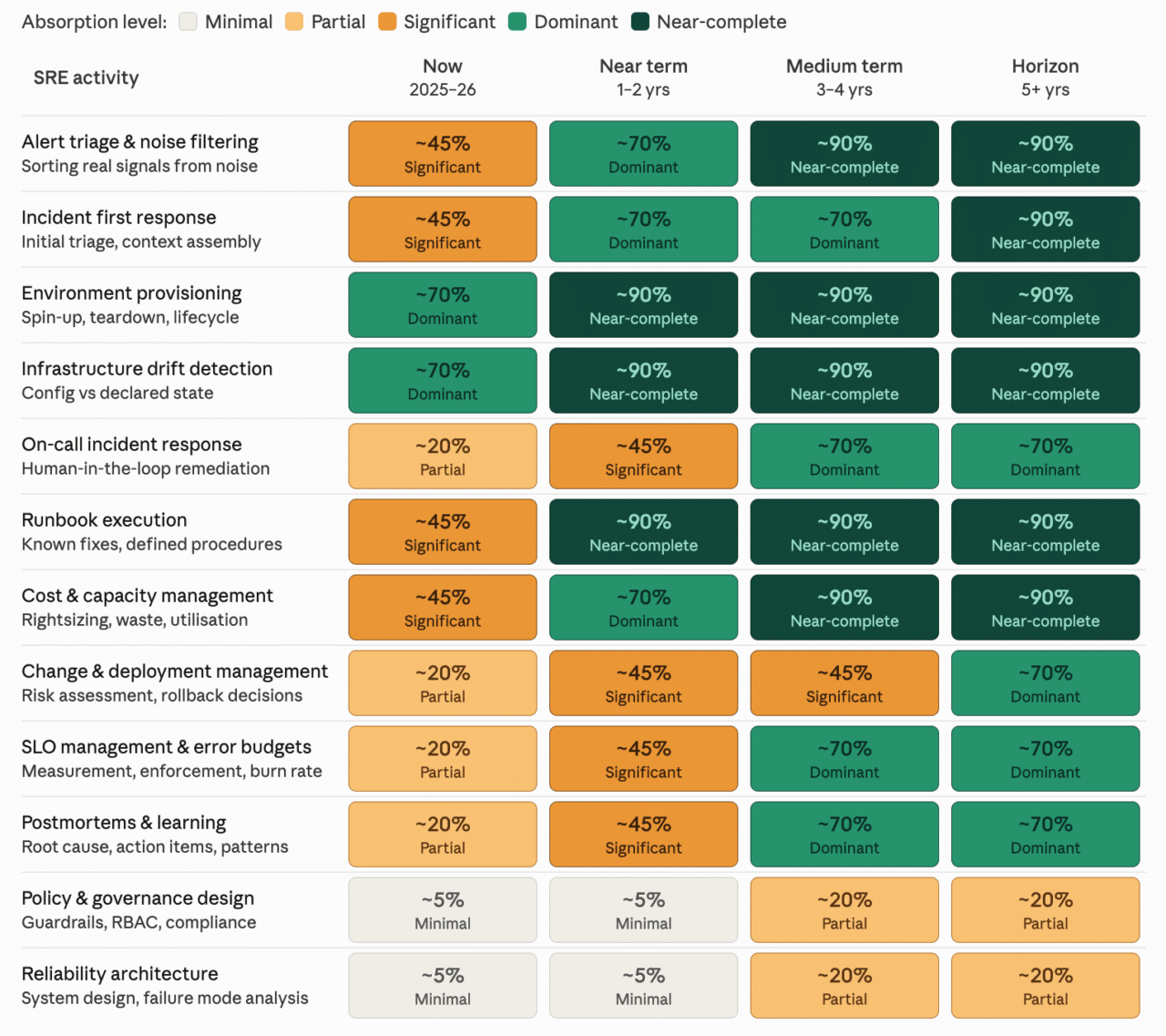
The activities that absorb fastest, environment provisioning, drift detection, alert triage, are precisely the ones that depend on governed infrastructure to function at their ceiling.
The pace of agentic AI development in operations has no precedent in enterprise software. Two years ago, autonomous SRE agents were theoretical. Today they are generally available across every major platform.
The organizations that have the infrastructure governance layer in place when that capability matures will extract dramatically more value from it than those who are still managing environments through ad hoc scripts and hoping their monitoring catches what their governance missed.
The investment decision is not “should we buy smarter monitoring.” It is “should we govern the infrastructure layer that makes everything above it, monitoring, agents, developer velocity, compliance, work properly.”
For engineering leaders making that decision, the answer is not particularly close.
— insert SRE article URL here once published: For a detailed analysis of how agentic AI reshapes the SRE role activity by activity, including an interactive tool mapping the transition timeline see: [The SRE Role Isn’t Changing. It’s Inverting.]]
Quali Torque is a purpose-built for this model, giving engineering teams agentic AI that works within guardrails, surfaces its work for human review, and develops the contextual awareness to become genuinely more capable over time.
To see Torque in action, visit the Torque playground, book a live demo focused on SRE and platform use cases to see how Torque plugs into your existing application pipelines and tooling.