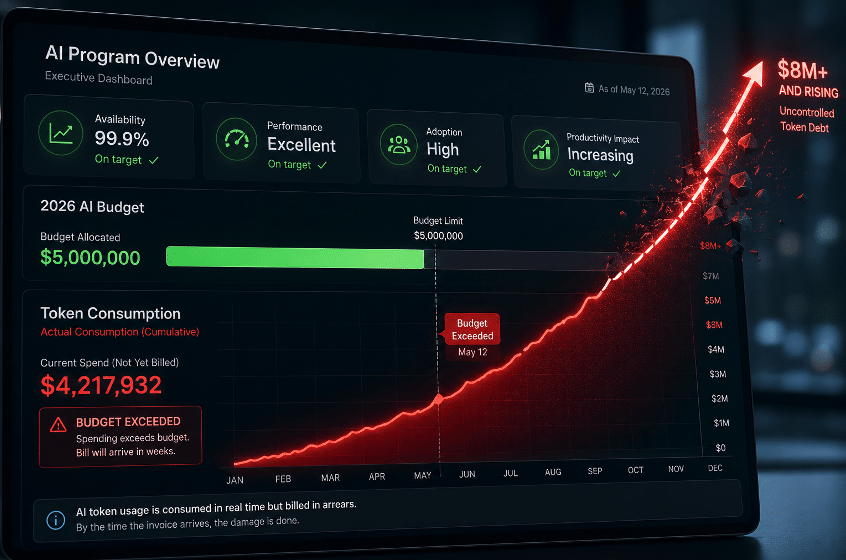
In April 2026, Uber’s CTO confirmed that the company had exhausted its entire 2026 AI coding tools budget in four months, with eight months of the year still to run. It was not a runaway project or a rogue team. It was 5,000 engineers using AI tools the way they had been encouraged to use them, at $500 to $2,000 per engineer per month in token costs. Around the same time, Microsoft revoked Claude Code licenses across one of its largest engineering divisions. The tools were not the problem, they were good enough that engineers used them constantly, and the constant use broke the budget math entirely.
Meta’s situation was more revealing. An internal memo to 6,000 employees flagged that internal AI usage was on track to cost billions of dollars in 2026 from employee use alone, distinct from capital expenditure on GPUs and data centers. Employees had consumed 73.7 trillion tokens in a single month, partly driven by an internal leaderboard called “Claudeonomics” that rewarded token volume. Meta’s CTO Andrew Bosworth responded: “All motion is not progress and token usage alone is not a measure of impact of any kind.” Meta is now building a centralized AI Gateway and implementing formal token budgets, scheduled for 2027.
These are not cautionary tales from organizations that moved carelessly into AI. Uber, Microsoft, and Meta are among the most sophisticated technology operators in the world. If they cannot govern token consumption at scale, the average enterprise faces a structurally harder version of the same problem, without the financial cushion to absorb the overruns while they figure it out.
The numbers explain why:
| Token Price Change (2024 to 2026) | Enterprise AI Bill Change (same period) | Consumption Growth per Developer (agentic) |
↓ 98% | ↑ 3× | 18.6× |
| Per-token prices collapsed as competition increased | Bills tripled despite cheaper unit pricing | Agentic tools multiplied volume, not just frequency |
Goldman Sachs forecasts a further 24-fold increase in token consumption by 2030, reaching 120 quadrillion tokens per month. The governance problem is not at peak. It is at the beginning. This article explains why tokens have become structurally unmanageable, and why the answer is not better dashboards, tighter procurement, or a new governance meeting. It is governance built into the infrastructure layer itself, at the point where tokens are created rather than after they have already been spent.
The scale problem nobody priced correctly
Most enterprises priced AI on chatbot economics: a user asks a question, the model responds, and the interaction ends. Agentic AI is a different category entirely. Josh Matthews from Cisco put it precisely: chatbot consumption is elementary, while agentic workloads consume tokens at 105 to 106 times that scale. The table below shows what that difference means in practice.
| Chatbot AI | Agentic AI | |
| Consumption pattern | Sporadic: one request, one response | Continuous: runs until stopped |
| Token volume per task | Hundreds to thousands | Millions to billions (10⁵–10⁶× higher) |
| Cost predictability | Bounded and forecastable | Highly variable, burst-driven |
| Budget risk | Low: capped by interaction volume | High: can exceed monthly budget in hours |
| Governance need | Monitoring and alerting is adequate | Provisioning-layer enforcement is required |
| FinOps tooling fit | Reasonable: retrospective review works | Poor: spend happens before tools can react |
Multiply the agentic column by the reality of how enterprises deploy AI in 2026. Most organizations run a mix of tools simultaneously: a frontier model API for reasoning tasks, an open-source model on-premises for sensitive data, a fine-tuned specialist model for a particular domain, AI-powered developer tools making their own API calls, and agent orchestration frameworks spawning multiple sub-agents per task. Each consumes tokens independently, with no coordination and no visibility into the others’ spend. None of the standard cost management frameworks were designed to see across all of them at once.
“Runaway token consumption is real. Our work with the Cisco team means customers can plan and contain that now. They won’t have bills showing up after seven events went past and they’ve spent a million dollars with nothing to show for it.” — Jonah Luck, Chief Product Officer, Sumer Sports, at Cisco Live 2026
The result is what could reasonably be called token debt, a form of financial liability that accumulates across AI tools, environments, and teams, largely invisible until it surfaces as a budget crisis. Cloud waste now costs enterprises approximately $270 billion globally in 2026, roughly 29% of all cloud spend, according to the Flexera State of the Cloud Report. Waste rates are rising for the first time in five years, reversing a downward trend that had been building since 2021. In April 2026, Deloitte published a CFO guide specifically on AI token economics, a topic that did not exist on finance radar 18 months earlier.
Why standard cost management fails here
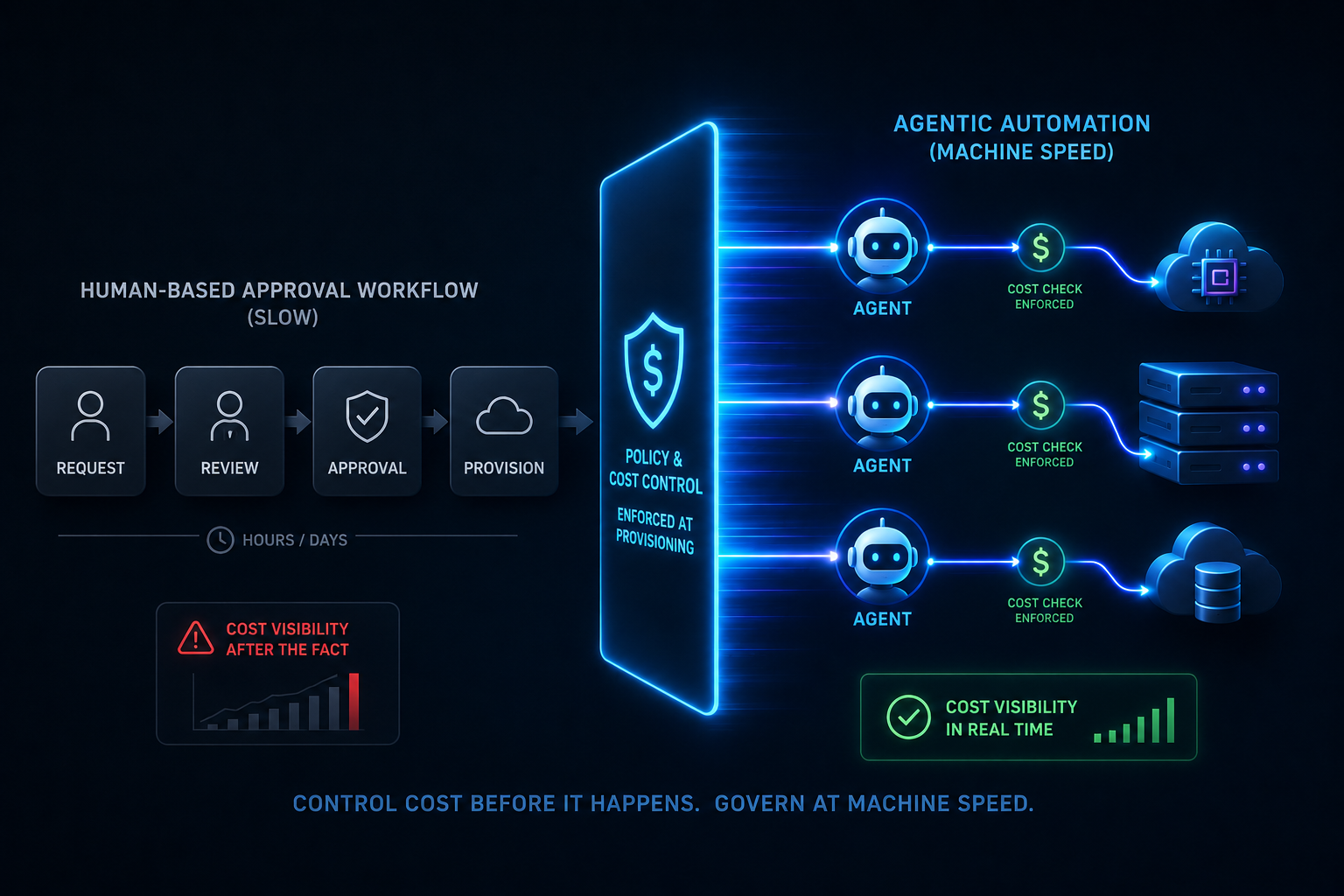
Standard cost management tools are built around a retrospective model: they ingest billing data, report on what was spent, and flag anomalies after the fact. That model works for infrastructure where spend accumulates slowly. It breaks down in two distinct ways when applied to agentic AI workloads.
Failure 1: Spend velocity is too high
- An H100 GPU cluster expected at $30/hr can spike to $100/hr during an unexpected traffic event as multi-step reasoning multiplies token usage simultaneously.
- By the time an anomaly detection system flags that the workload has exceeded a third of its monthly budget in a single day, the spend has already happened.
- Alerting after the fact is not cost control. It is cost documentation.
Failure 2: Tokens do not map to infrastructure units
- In a multi-agent environment, token consumption is generated at multiple layers simultaneously: model API calls, the orchestration layer, tool calls made by agents, and retrieval processes feeding them context.
- Each layer has its own pricing model, none of them natively consolidated.
- Trying to understand total token cost from a billing dashboard is like trying to understand a factory’s production costs by reading the electricity bill.
50% of cloud waste occurs at the moment resources are provisioned before any monitoring tool has the chance to intervene.
You cannot observe your way out of a provisioning problem.
The framework built for this problem cannot solve it
There is an entire professional discipline, FinOps, specifically chartered to govern cloud spend. With 98% of practitioners now managing AI spend (up from 31% two years ago), the community is fully engaged with AI workloads. The situation is getting worse, not better, because the framework was built for a different era of infrastructure. The evidence below is drawn from the community’s own published research.
| The Data | What It Actually Means |
| 12% of enterprises say their FinOps framework is not adapted for AI cost management (Flexera 2026) | Given that survey respondents self-select toward more mature practices, the real proportion across the broader market is almost certainly higher. |
| 27% cite unpredictable, bursty AI workloads as their top cost challenge (Flexera 2026) | This is a provisioning problem, not a reporting problem. No monitoring tool can act before spend occurs. |
| 23% cite unoptimized GPU utilization across AI tasks (Flexera 2026) | GPU resources are allocated at provisioning. By the time utilization data is available, the waste has already accumulated. |
| 98% of FinOps practitioners now manage AI spend, up from 31% two years ago (FinOps Foundation 2026) | Full engagement with AI workloads has not reversed rising waste. Framework adoption is not the same as framework effectiveness. |
The FinOps Foundation’s State of FinOps 2026 opens with: “FinOps is no longer just explaining past spend.” This is the community acknowledging that for most of its existence, the practice has spent its time explaining past spend without preventing future waste.
One of the most senior FinOps practitioners in the world, quoted in the Foundation’s own flagship agentic AI article, said that discussions about shifting FinOps left still do not feel like they are going to have the impact. The instinct to govern at provisioning exists inside the community. The mechanism to do it does not exist inside the framework.
That closes off the easy answer. If the discipline built for cloud cost governance cannot govern AI token costs at the speed and layer where they are created, the solution is not a better FinOps program. It requires enforcement at the infrastructure layer, at provisioning, before tokens flow.
What governance actually means in this context
Governance is not a policy. It is a mechanism.
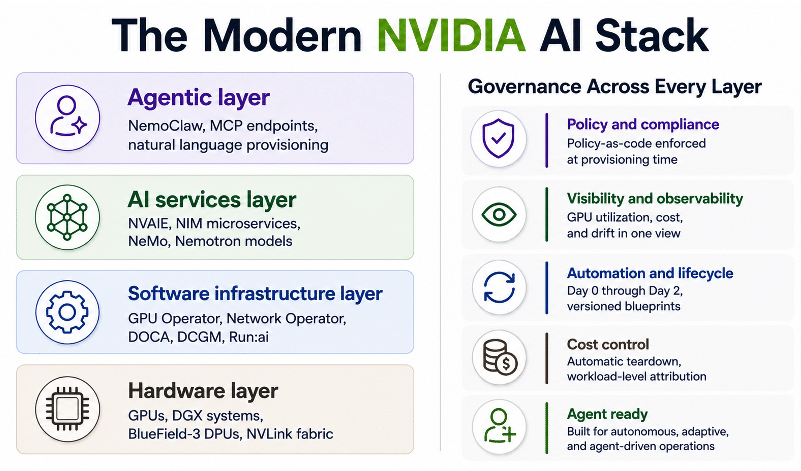
When people talk about AI governance, they often mean policy: acceptable use guidelines, risk frameworks, procurement criteria. Those things matter, but they do not control token costs. The governance that controls costs is embedded in infrastructure, the rules that determine what can be provisioned, by whom, under what constraints, and with what automatic lifecycle behavior.
Effective infrastructure governance has five components relevant to the token problem:
- Provisioning controls: what AI resources can be deployed and what configuration constraints apply at the point of deployment, not after.
- Budget guardrails: hard limits on spend per environment, per team, or per workload, enforced before tokens flow rather than flagged after they have.
- Tagging and attribution: automatic metadata that attaches every resource to an owner, a project, and a purpose, so token spend is attributable rather than anonymous.
- Lifecycle policies: automatic shutdown, expiry, and teardown rules that prevent AI environments from running indefinitely when no active workload requires them.
- Drift detection: continuous comparison between the intended configuration of an environment and its actual state, with automatic remediation when they diverge.
Each of these mechanisms exists at the infrastructure layer, not the dashboard layer. They operate at provisioning time and continuously thereafter, without waiting for a billing cycle to close.
The environment as the unit of governance
The insight that changes how you think about token cost management is this: the environment is the right unit of control, not the individual resource, not the API call, not the workload. An environment is a complete, bounded collection of resources assembled for a specific purpose: compute, networking, storage, AI model runtimes, the orchestration layer, tool integrations, and the configuration that connects them. It has an owner, a declared purpose, and a lifecycle with a defined start and end.
When token consumption is managed at the environment level, four things become possible that are impossible when you try to manage it resource by resource:
- Budget by purpose: set a total cost budget covering all AI calls within the environment, regardless of which tool makes them.
- Time-to-live enforcement: terminate the environment when it is no longer needed, automatically reclaiming all resources it contained.
- Audit by intent: record what the environment was for, which team owned it, and how much it consumed over its lifetime.
- Governed replication: deploy the same environment to a different cloud, region, or team with governance constraints embedded from the start.
This is the operational model that makes multi-tool AI deployments governable at enterprise scale.
| Capability | What It Does | Problem It Solves |
| Blueprint-based deployment | Every environment is provisioned from a defined template covering compute, networking, storage, model runtimes, and policy | Eliminates misconfiguration and enforces governance before a single token is consumed |
| Self-service with governance | Teams deploy from a pre-approved catalog; approval workflows apply where required | Removes the choice between speed and control, both are built into the same mechanism |
| Cost tracking with context | Spend is tied to the environment, team, project, and purpose in real time | Transforms cost data from a billing artifact into an actionable operational signal |
| Time-to-live enforcement | Every environment carries an expiry policy; decommissioning is automatic | Prevents forgotten environments from consuming tokens and GPU hours indefinitely |
| Drift detection | Continuous comparison of intended vs. actual environment state, with auto-remediation | Stops configuration drift from silently increasing costs or creating security exposure |
Environments as Code, deployed from blueprints
In Torque, an environment is defined as code: a blueprint specifying every component, configuration, policy, and integration that makes up a complete, purpose-built deployment. That blueprint can cover physical servers, virtual machines, containers, Kubernetes clusters, serverless functions, cloud-native services across AWS, Azure, and GCP, and on-premises infrastructure, all in a single definition.
When a team deploys from a blueprint, they get exactly what it specifies: the right compute, the right model runtimes, the right networking, and the right governance constraints, including token budget limits, cost alerts, and automatic teardown policies. They cannot provision more than the blueprint allows, forget to tag resources, or leave an environment running indefinitely. The governance is not added later. It is baked in from the start.
Self-service that does not sacrifice control
One structural cause of token debt is that the teams consuming AI infrastructure are not the same teams responsible for managing its costs. When those teams need a new environment, they either wait for specialists to provision it manually, killing velocity, or provision it themselves without governance, killing the budget.
Torque resolves this with a self-service model that is governed from the start. Teams request environments from a catalog of pre-approved blueprints. Approval workflows apply where required. The environment is provisioned automatically with all governance constraints embedded. The requester gets speed, the platform team retains control over permissible configurations, and the finance team gets accurate attribution data from day one. Nobody circumvents governance to get speed, and nobody trades speed for governance.
Real-time cost tracking with context
Standard cost tools track spend. Torque tracks spend in context: tied to the environment, team, project, and declared purpose. That context transforms cost data from a billing artifact into an operational signal.
- A $40,000 monthly AI spend attributed to a specific production environment can be evaluated against the business value it is delivering.
- $8,000 coming from an environment idle for two weeks can be acted on immediately, not discovered at month end.
- A data science environment that has consumed three times its token budget in a week points directly to the specific workload causing it, rather than an aggregated line item.
Lifecycle enforcement that reclaims idle AI spend
A significant fraction of AI infrastructure waste comes from environments that outlive their purpose: model development environments from sprints that ended weeks ago, test deployments never torn down, proof-of-concept environments whose projects were cancelled but whose GPUs keep drawing power.
Torque’s time-to-live policies make this structurally impossible at scale. Every environment has a defined lifecycle. When it ends, the environment is automatically decommissioned and its resources reclaimed. Teams can request extensions, but the default is expiry, not indefinite operation. For agentic workloads in particular, an agent running in a forgotten environment is not idle in the way an unused VM is idle, it is actively consuming tokens, making API calls, and processing data, running up a bill nobody is watching.
The multi-tool problem, specifically
A typical enterprise AI deployment in 2026 includes some combination of a general-purpose frontier model API, a specialized on-premises model for sensitive data, AI-assisted developer tooling making its own API calls, RAG pipelines consuming tokens for both retrieval and generation, and agent orchestration frameworks spawning multiple sub-agents per task.
Each tool operates in its own silo, with its own API key, billing, and usage patterns, none of them coordinating with the others. The honest answer to “how much did our AI program cost this month” is, for most enterprises, that nobody knows with any precision.
The environment model resolves this directly. When all tools are deployed as components of a governed environment, they operate under the same governance constraints. The total cost, across every tool, every API call, and every token consumed by every component, is tracked as a single unit. The budget guardrail applies to the aggregate. The time-to-live policy terminates all of them together when the environment expires.
FinOps is now token economics. The enterprises that treat AI deployment as a manufacturing process, with repeatable blueprints, automated governance, and defined lifecycles, will be the ones that generate returns on their AI infrastructure investment. The ones that treat it as an IT project will find that the factory never reaches production capacity.
The on-premises equation
Charlie Meyers, CTO of Monumental Sports and Entertainment, made a point at Cisco Live worth taking seriously: “FinOps is really token economics now. On-premises capabilities are huge. It drives security, privacy, and cost control.”
The cloud migration parallel is apt. Enterprises were told that moving to the cloud would be cheaper and faster. Many discovered that for continuous, sustained workloads, the variable cost model of public cloud was actually more expensive than owning the infrastructure once you accounted for the full cost at scale. The same dynamic is playing out in AI. For sporadic workloads, public cloud token consumption is the right model. For continuous agentic workloads, with agents running 24 hours a day, the economics of on-premises AI infrastructure often become compelling.
On-premises AI only delivers on that promise if it can be commissioned efficiently and governed continuously once running. The sixteen-week deployment cycle that Jeremy Foster described at Cisco Live, with enterprises hand-assembling AI stacks across compute, networking, storage, software frameworks, security tooling, and ISV applications, destroys the economic advantage before the first production workload runs. Even once the infrastructure is live, without environment-level governance over what runs on it, token costs on an on-premises cluster are no more controllable than they are in the cloud.
Torque’s blueprint-based deployment, lifecycle enforcement, and cost attribution apply equally to on-premises infrastructure. You own the hardware; Torque governs what runs on it, how long it runs, and what it costs, regardless of where it sits.
At Cisco Live in June 2026, Quali also announced Stack Automation, a deployment automation platform co-engineered with Cisco and available exclusively through the Cisco partner network from August 2026. Stack Automation addresses the infrastructure commissioning problem for Cisco AI infrastructure stacks and is a separate product from Torque, focused on the deployment layer rather than ongoing environment governance.
What this means practically
The token management problem will not be solved by better dashboards or more granular cost reports. It requires structural changes to how AI environments are provisioned, governed, and decommissioned. Three priorities stand out:
- Define environments before workloads. Before deploying an AI agent, a model, or a multi-tool pipeline, define the environment it will live in: its resource constraints, cost budget, time-to-live, and attribution metadata. Governance is not something you add later. It is the container into which the workload is deployed.
- Govern the aggregate, not the component. In multi-tool deployments, managing cost tool by tool does not work. The environment is the right boundary for cost accountability: one budget, one lifecycle, one set of governance constraints applied to everything running inside it.
- Make lifecycle enforcement the default. Every AI environment should have a defined expiry. Extensions should require a deliberate action. This is not a process change; it is an infrastructure capability that must be built into your deployment platform.
Token debt is a new form of technical debt. Like traditional technical debt, it accumulates quietly, compounds over time, and becomes expensive to unwind once embedded in your operational model. Unlike traditional technical debt, it shows up directly on the CFO’s desk, often without warning and without a clear explanation of where it came from.
The enterprises that build governed, environment-first AI infrastructure from the start will avoid that conversation. The ones that treat token management as something to figure out later will be having it sooner than they expect.
Quali Torque is a purpose-built for this model, giving engineering teams agentic AI that works within guardrails, surfaces its work for human review, and develops the contextual awareness to become genuinely more capable over time.
To see Torque in action, visit the Torque playground, book a live demo focused on SRE and platform use cases to see how Torque plugs into your existing application pipelines and tooling.
Sources
Flexera State of the Cloud Report 2026 · FinOps Foundation State of FinOps 2026 · The Next Web, “Token prices fell 98%. Enterprise AI bills tripled” (June 5, 2026) · Fortune, “Microsoft reports expose AI’s real cost problem” (May 2026) · The Decoder, “Meta shifts from tokenmaxxing to token managing” (June 2026) · Uber CTO Praveen Neppalli Naga, The Information (April 2026) · Goldman Sachs, agentic AI token consumption forecast (2026) · Deloitte, CFO Guide to AI Token Economics (April 2026) · Cisco Live 2026: NVIDIA/Cisco center stage session (June 2026)