A lot of companies have acquired NVIDIA infrastructure. Far fewer have figured out how to operate it.
That distinction matters more than most engineering leaders realize. The hardware is the easy part. NVIDIA GPUs are available. Blackwell is shipping. DGX Spark and DGX Station are accessible as never before. The bottleneck has shifted entirely to the layer above the hardware, the software stack that turns GPU capacity into production-ready AI infrastructure. And that layer is genuinely hard.
If you have read our earlier post on the enterprise AI deployment problem, you already know the broad picture: enterprise AI has a deployment problem, not a hardware problem. The hardware exists. What is missing is the operational layer that takes you from raw NVIDIA compute to a governed, reproducible, production-ready environment. That post explained the problem at the stack level. This one goes deeper, into what the NVIDIA stack actually consists of, where the operational gaps live, and what it takes to close them.
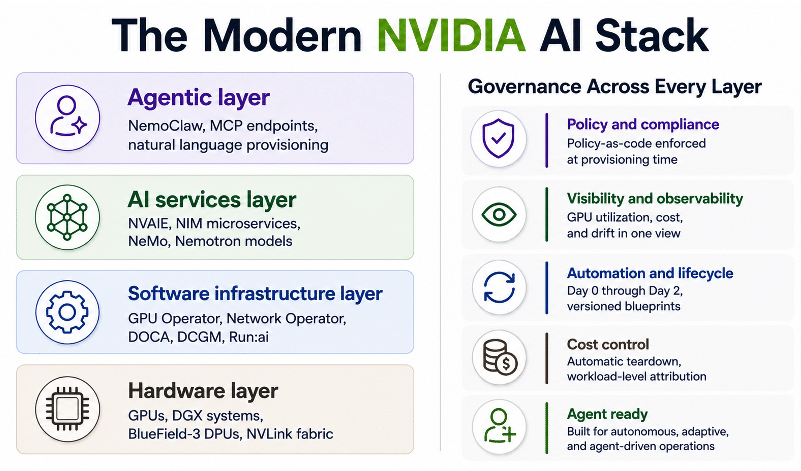
The NVIDIA AI stack is not one thing
When engineers talk about “NVIDIA AI infrastructure,” they usually mean several different things at once, and conflating them is where the trouble starts.
There is the hardware layer: GPU servers, DGX systems, BlueField-3 DPUs handling offloaded networking and security, and the NVLink fabric connecting them. This is the substrate.
Sitting on top of that is the software infrastructure layer: the GPU Operator managing driver and toolkit installation, the Network Operator handling InfiniBand and Ethernet configuration, DOCA Platform Framework enabling DPU service chaining, DCGM collecting GPU telemetry, and Run:ai scheduling workloads across GPU pools. These components turn the hardware into something workloads can actually run on.
Above that is the AI services layer: NVIDIA AI Enterprise (NVAIE) providing the licensing and compliance framework, NIM microservices delivering inference endpoints, NeMo components handling retrieval, guardrails, and evaluation for agentic and RAG pipelines, and Nemotron models, now spanning the full Nano to Ultra range, providing the model layer for fine-tuning and production inference.
And sitting at the top, increasingly, is the agentic layer: NemoClaw enabling autonomous AI agents to generate, optimize, and self-heal infrastructure definitions, with the entire stack addressable through natural language via an MCP endpoint.
Each layer has its own deployment requirements. Each has its own day-2 operational demands. And each has to work correctly alongside everything else for the stack to deliver value. The challenge is not deploying any one of these components. It is deploying all of them together, consistently, across teams, across clusters, and across the full environment lifecycle.
Where the operational gaps actually live
Most organizations running NVIDIA infrastructure have parts of this working. Almost none have it working end-to-end in the way that scales.
The patterns we see are consistent.
Licensing is managed manually or not at all. NVAIE entitlement validation is a prerequisite for running NIMs or Omniverse components. Organizations that handle this at the individual blueprint or environment level create an immediate compliance risk at scale. License state becomes impossible to audit, and enforcement becomes inconsistent. The correct approach, platform-level credential management with automatic pre-execution validation, requires deliberate design. It does not happen by accident.
GPU Operator deployments drift. The GPU Operator manages drivers, the CUDA toolkit, and DCGM across a cluster. When it is deployed as a one-time configuration rather than a version-pinned, lifecycle-managed blueprint component, it drifts. Driver versions diverge across nodes. DCGM configurations fall out of sync. Reconfiguration becomes a manual, risky operation. The Operator needs to be managed as code, with day-2 upgrade workflows built in from the start.
NIM endpoints are not reproducible. A data scientist can stand up a NIM inference endpoint manually. What they cannot easily do is stand up the same endpoint, with the same model selection, the same scaling configuration, and the same secrets management, every time, identically, across environments. When inference environments are not defined as versioned blueprints, each deployment becomes a snowflake. Debugging becomes harder. Cost attribution becomes impossible. Rollbacks are not an option.
NeMo component assembly is fragmented. For agentic and RAG workloads, the required stack includes NIM endpoints, NeMo Retriever, Guardrails, and Evaluator microservices, vector data services, and NGC artifact references. Organizations assemble these components manually, environment by environment. The result is configuration inconsistency across teams and a support burden when things break, because no two environments are quite the same.
GPU cost is invisible until it is too late. GPU capacity is expensive. Idle GPU environments, fine-tuning jobs that completed but were never torn down, inference endpoints left running after a demo, training environments that were never cleaned up, are a significant and largely invisible cost. Without automatic teardown policies and workload-level cost attribution, FinOps teams are reviewing invoices rather than preventing waste.
Governance does not survive scale. At pilot scale, a single team managing a handful of environments can enforce governance through process. At production scale, with multiple teams, multiple GPU clusters, on-premises and cloud infrastructure, and AI agents also provisioning environments through MCP endpoints, process-based governance collapses. You need policy-as-code, enforced at provisioning time, that applies equally to human-initiated and agent-initiated deployments.
What the operational model needs to look like
The pattern that works, and that Torque implements across the full NVIDIA stack, is treating every layer of the NVIDIA AI stack as a governed, versioned blueprint component.
That means the GPU Operator is not installed. It is deployed from a version-pinned blueprint, with the surrounding prerequisites, drivers, toolkit, DCGM, defined in the same environment. Day-2 upgrade workflows are part of the blueprint definition.
It means NIM microservices are not launched manually. They are provisioned from NGC as blueprint components, with model selection, replica scaling, GPU affinity, and secrets management all wired in. From NIM selection to a running inference endpoint in under an hour, reproducibly.
It means NeMo component assembly is not done environment by environment. Retriever, Guardrails, Evaluator, vector data services, and NIM endpoints are assembled into a single governed blueprint. The same blueprint runs identically whether a data scientist launches it through the self-service portal or an AI agent requests it through the MCP server.
It means NemoClaw agent environments, Nemotron 3 Super serving, OpenClaw gateway, OpenShell sandboxing, are provisioned from versioned infrastructure definitions, with automatic teardown enforced when agent tasks complete. GPU resources do not accumulate. Costs do not spiral. Every environment is auditable.
And it means all of this operates under a consistent governance model: NVAIE license compliance enforced at the platform credential level, role-scoped multi-tenant isolation across DGX Spark, DGX Station, on-premises clusters, and cloud GPU infrastructure, cost attribution tagged at the environment level, and policy-as-code applied at provisioning time, before the resource exists, not after it is already running.
| Operational Gap | Risk If Unresolved | What Torque Delivers |
|---|---|---|
| License management | Compliance exposure at scale | Platform-level NVAIE validation, pre-execution |
| GPU Operator drift | Driver divergence, manual remediation | Version-pinned, lifecycle-managed blueprints |
| NIM endpoint inconsistency | Unreproducible environments, no rollback | Governed blueprints with model, scale, and secrets wired in |
| NeMo stack fragmentation | Configuration inconsistency, support burden | Single governed blueprint across full agentic stack |
| Invisible GPU cost | Waste accumulates silently | Automatic teardown policies, workload-level cost attribution |
| Governance at scale | Policy enforcement collapses post-pilot | Policy-as-code applied equally to human and agent provisioning |
The DPU layer is where most organizations leave value on the table
One aspect of the NVIDIA stack that gets less attention than it deserves is the BlueField-3 DPU layer and DOCA Platform Framework.
The value proposition for DPUs is clear: offloading networking and security processing from CPU cores to purpose-built DPU infrastructure frees host CPU capacity for AI workloads and enforces network security at the hardware level. In GPU-dense environments running latency-sensitive inference workloads, that matters.
The operational challenge is that DOCA and DPF Operator deployment is typically decoupled from the rest of the AI stack. Teams provision GPUs, stand up the GPU Operator, deploy their NIM endpoints, and then treat DPU service chaining as a separate infrastructure concern, managed separately, configured separately, and therefore drifting independently of everything else.
The correct model is to orchestrate DPF Operator installation and BlueField-3 service chaining as part of the same environment lifecycle as the rest of the stack. When the environment comes up, offloaded networking and security services come up with it, not as a follow-up task, not as a separate ticket, but as part of the same governed, versioned blueprint.
BlueField-3 DPU and DOCA Platform Framework
The DPU layer is typically decoupled from the rest of the AI stack, managed separately, configured separately, and drifting independently.
| Typical Approach | Torque Governed Lifecycle | |
| Deployment sequencing | GPUs are provisioned, the GPU Operator is deployed, NIM endpoints go up, and then DPU service chaining is treated as a separate infrastructure task, handled on a different ticket by a different team. | DPF Operator installation and BlueField-3 service chaining are orchestrated as part of the same environment lifecycle. When the environment comes up, offloaded networking and security services come up with it. |
| Config drift | DPU configuration drifts independently of the GPU stack. Security policies and network offload settings fall out of sync with the compute layer, creating gaps that are difficult to detect and expensive to remediate. | DPU configuration is version-pinned in the same governed blueprint as the rest of the stack. Drift detection spans the full environment, including the DPU layer, not just the compute components. |
| CPU capacity for AI workloads | Networking and security processing runs on host CPU cores. In GPU-dense, latency-sensitive inference environments, this is a direct tax on the resources that should be serving AI workloads. | Offloaded networking and security processing frees host CPU capacity for AI workloads. The DPU layer delivers its intended value because it is consistently deployed and consistently managed as part of the governed stack. |
Run:ai and the scheduling layer
GPU scheduling and GPU environment governance are two different problems, and they require two different tools.
Run:ai handles in-cluster GPU scheduling: allocating GPU resources to workloads, managing quotas, and maximizing utilization across a cluster. It is purpose-built for that problem and it solves it well.
What Run:ai does not solve is the environment lifecycle question: provisioning the infrastructure, enforcing compliance and cost policy, managing day-2 operations, and decommissioning environments when work is complete. That is what Torque handles.
The integration model is straightforward. Torque stands up and configures Run:ai as a blueprint component, then governs the environments that consume the GPU pools Run:ai manages. Run:ai handles in-cluster scheduling. Torque handles provisioning, policy, and lifecycle. Neither tries to do the other’s job.
Run:ai and the scheduling layer
GPU scheduling and GPU environment governance are two different problems. Conflating them leaves both unsolved.
| Run:ai | Torque | |
| Primary responsibility | In-cluster GPU scheduling: allocating GPU resources to workloads, managing quotas, and maximizing utilization across a cluster. | Environment lifecycle: provisioning infrastructure, enforcing compliance and cost policy, managing day-2 operations, and decommissioning environments when work is complete. |
| What it does not solve | Run:ai does not provision the infrastructure beneath the cluster, enforce cost or compliance policy at the environment level, or manage the lifecycle from day 0 through decommission. | Torque does not perform in-cluster GPU scheduling or manage workload quotas within a running cluster. That is Run:ai’s job, and it does it well. |
| Integration model | Torque stands up and configures Run:ai as a blueprint component, then governs the environments that consume the GPU pools Run:ai manages. Run:ai handles in-cluster scheduling. Torque handles provisioning, policy, and lifecycle. Neither tries to do the other’s job. | |
Governance is not a later problem
The governance gap post covered why governance is the blind spot of the agentic era. The same logic applies to NVIDIA infrastructure specifically, and it is worth being direct about why.
When AI agents can provision NVIDIA GPU environments through natural language via an MCP endpoint, the volume of provisioning requests, and the potential for cost and compliance exposure, scales in a way that human review cannot keep up with. An agent that can stand up a NemoClaw environment, a NIM inference cluster, or a Nemotron fine-tuning stack on demand is an agent that can also accumulate GPU capacity at enterprise scale if the governance layer is not in place.
The answer is not to restrict agent access to infrastructure. That defeats the purpose. The answer is to ensure that every environment an agent provisions is subject to the same policy enforcement, cost attribution, and automatic teardown as a human-initiated deployment. When governance is a property of the provisioning system rather than a review process applied after the fact, agent-initiated and human-initiated deployments are equally safe.
That is what building on a governed infrastructure platform gets you. The agentic access is a capability. The governance is what makes that capability safe to use at scale.
What breadth of coverage actually means
Torque’s NVIDIA ecosystem coverage spans the full stack: NVAIE licensing, GPU Operator and Network Operator, DPF Operator and BlueField-3 service chaining, NIM Operator and NIM microservices, NeMo components, the Nemotron 3 model family from Nano through Ultra, NemoClaw agentic tooling, Run:ai scheduling integration, DCGM telemetry exposure, and NGC as the artifact registry for all of the above.
Validated on DGX Spark, DGX Station, on-premises GPU clusters, and cloud GPU infrastructure including AWS, Azure, CoreWeave, Nebius, and Oracle, and among the earliest software partners to validate on Blackwell architecture.
That breadth is not incidental. It is the point. The operational value of governing NIM endpoints while leaving the GPU Operator unmanaged is limited. The value of enforcing NVAIE license compliance while leaving NeMo component assembly inconsistent is limited. The NVIDIA stack works as a system. Governance has to work at the same level.
If you are running NVIDIA infrastructure in production, or planning to, the question to ask is not whether your hardware is capable. It almost certainly is. The question is whether your operational model, your provisioning, governance, lifecycle management, and cost controls, can scale at the same rate as your GPU capacity.
The hardware problem is solved. The operational problem is where enterprise AI either compounds or stalls.
For IT and infrastructure leaders building out an AI stack that is meant to last, and meant to scale, this is what leading AI infrastructure management looks like in practice.
See how Torque manages the full NVIDIA AI stack
NemoClaw press release: Quali’s Torque Platform Brings Enterprise Governance to NVIDIA NemoClaw
Nemotron 3 press release: Quali’s Torque Platform Extends NVIDIA Ecosystem Support to Nemotron 3
Read the previous blog: Managing Autonomous AI Agents at Enterprise Scale Is Now a Business Imperative
To see Torque in action, visit the Torque playground, or book a live demo to see how Torque manages the modern AI stack.